フリーアイコン
http://gigazine.net/index.php?/news/comments/20100817_woocons1/
http://gigazine.net/index.php?/news/comments/20091206_webiconset/
http://gigazine.net/index.php?/news/comments/20100312_elegantthemes_iconpack/
http://phpspot.org/blog/archives/2010/08/2010.html
http://e0166.blog89.fc2.com/blog-entry-632.html
http://pixelresort.com/blog/category/Showcase/
http://www.freeiconsweb.com/free_icon.html
フリーPSD・テーマ
http://freepsdtheme.com/
http://www.smashingmagazine.com/2010/08/19/100-free-high-quality-wordpress-themes-for-2010/
http://www.stumbleupon.com/su/4OhCh5/www.noupe.com/freebie/80-useful-psd-templates-for-designers.html
配色ツール
http://www.color-fortuna.com/color_scheme_genelator2/
サウンド
http://www.freesound.org/

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
August 18, 2010
Tools - free icon etc
Posted by funa : 04:37 PM | Web | Comment (0) | Trackback (0)
August 9, 2010
ER
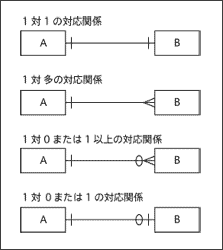 ERダイヤグラムの作図ルールのまとめ。ER図
ERダイヤグラムの作図ルールのまとめ。ER図■要件定義
https://qiita.com/Saku731/items/741fcf0f40dd989ee4f8
発注者に満足感があり、下流で滞りなく開発ができソフトウェアが納品されればいい
色んな考え方ややり方があるので臨機応変に、どこまでが範囲か確認できればいいが
■設計者から開発者に渡すっぽい上流工程
///Why:システム開発の目的(要望)
現状の課題
ゴール(本来あるべき状態)
現状とゴールのギャップ(解決すべき課題)
///What:何をもって課題を解決するのか
システム導入後の業務フロー
機能要件
システムに実装する機能一覧
非機能要件
処理スピード、セキュリティ など様々
///How:具体的な使い勝手と実装方法(システム設計)
基本設計
画面設計(UI設計)
機能設計
データ設計
詳細設計
クラス図、シーケンス図
システムアーキテクチャ
各部位を実装する技術 など様々
■ビジネスと開発の両側で合意を取るっぽい上流工程
///要望:解決すべき課題(発注者タスク)
現状の課題
ゴール(本来あるべき状態)
現状とゴールのギャップ(解決すべき課題)
///要求:システムに実装したい機能(発注者タスク)
企画の背景(解決すべき課題)
課題解決に必要なシステムの概要
具体的に実装したい機能一覧
///検討:要求の実現性を考える(開発者タスク)
技術的に開発可能か?
予算はどの程度必要か?
納期はいつ頃になるか?
///提案:検討した結果を発注者に戻す(開発者タスク)
実装できる機能
請求する金額
納品できる期日
///要件:双方が合意した決定事項(発注者・開発者が協議して決める)
システムに実装する機能一覧
納期、請求額の目安が記載されるケースも
==========
■階層化されたシステム要件一覧(要件ツリー)の例
利益管理の強化に貢献すること
月中であっても利益ベースでの予実達成状況を監視できること
受注単位で粗利がわかるようになること
顧客サービスの改善に貢献すること
受注時に納期回答できるようであること
入荷かう出荷までロットをトレースできること
在庫管理レベルの向上に貢献すること
余剰在庫や死蔵品を50%削減できること
在庫データには常に現在の在庫状況が反映されていること
作業効率の向上に貢献すること
バーコードラベルによって入出荷作業が簡便化されているとと
配車計画をある程度自動化できること
■機能要件一覧の例
"利用者は全支店の営業部門の所属者とする。(支店は全国27箇所)"
担当者毎に、参照、登録・更新・削除、承認の権限が付与できること。
承認者が不在の場合に代理承認できること。
"パソコンだけでなく、スマートフォンからでも操作が可能なこと。(ブラウザ利用)"
過去の案件を検索できること
画面に一覧表示した内容をCSVファイルでダウンロードできること
過去の案件をコピーして新しい案件が作成できること
進捗の途中で、異動や退職によって離任する人がいた場合でも、承認者の変更ができること。
進捗の途中で、組織が変更になった際に、承認ルートの再設定ができること。
組織を兼務する利用者に対応できること。
承認や差し戻しをした際、次の担当者にメールが発信されること。
ユーザーとパスワードによるログイン機能があること
ユーザーの照会、登録、更新、削除が可能なこと
etc.
■非機能要件一覧の例
サービス停止後、再開までの時間:2時間未満。事前に業務調整をした上であれば2時間程度は許容できる。
バックアップデータの復旧時点:障害発生時点。
データ復旧までの時間:1営業日以内。急ぎの申請はメールや電話ベースで対応可能。
同時に利用されるユーザ数:1%程度と想定。10名。
ログの保管期間:2週間
特に応答速度が求められる操作および速度:5秒以内の表示。
通常の運用時間:朝6時〜夜22時までをシステム稼働時間とする。
バックアップの保存期間:次回バックアップ取得まで登録データ:3年
計画停止の有無:不定期に実施。実施する際は関係者の合意を得る。
移行作業完了後の3ヶ月間は初期稼働確認期間とし4ヶ月目からを本稼働とする。
ウィルス定義ファイルは自動更新とする。
etc.
==========
■工程を4つ程度に分けてしまう
1)上流工程(要件定義、基本設計、現状分析)
2)下流工程(詳細設計、実装、テスト)
3)ネットワーク設計・管理
4)プロジェクト管理
上流工程での注意
業務モデリング、データモデリング、機能モデリングを念頭に要件定義
要件定義するまえにPDCA調査もあり(営業を省略したいが本当に良いのかどうか)
基本設計書は拡散思考/自由発想で作っても良い
旧態依然になりがちな点に注意(先進、業務改善、便益を入れる)
基本設計書には全体像、画面、運用、セキュリティは特に担当者が知りたいことを盛る
要件と設計書の対応関係、WhatとHowは必須だがWhyもあった方が開発者も分かり易い
行間は読まれない、さりとて資料は把握はし易い方がいい
時間は23:59までか定時終了18:00までか等データは細かく確認
モックがあれば解決?
非機能要件について
http://www.aimc.co.jp/blog/p-4283/
テクニカルレビューは関係のない他の技術者に確認し妥当性を問う、ユーザ希望なのでとは言わない事
↓↓↓↓↓↓
■上流工程での成果物
-要件定義書
要望を箇条書き
前提となるハードやNWや業務フローを添付
-システム方式設計書(性能、信頼性、保守・運用、セキュリティを含む)
非機能要件一覧 (https://pm-rasinban.com/kinou-hikinou にサンプル有)
ユースケースシナリオ
システム構成図
-画面設計(機能、アクション、遷移)
ワイヤフレーム/モック/プロトタイプ
-データ設計(項目、ドメイン定義、制約、値域、コード仕様、ネーミング、データモデルER)
細かな所まで詰める(値段変動、合計値の格納)
-業務プロセス設計
業務フローと担当部署用の業務モデル
-既存システム調査報告書
-プロジェクト計画書
※業務フローと各担当部署用の業務モデル、データモデル、機能モデルがあれば納得感はある
■下流工程での成果物
-システム詳細設計書
プログラム仕様書、DBテーブル定義、ミドルウェアパラメータ?、業務マニュアル
==========
■システム化のときに考慮すべき要素
コンピュータの五大機能:入力/出力/記憶/演算/制御(CPU/MB)→入力/出力/記憶/演算の4つでいいかも
オフィスオートメーション(紙の作業を電子化):PCやFAX等の導入で書類作成/保存/検索/送付などの事務を合理化/自動化した
インターネット化、マーケティングオートメーション、メール化、電子マネー化、AIロボット化
処理を早く多く自動で簡単にメンテフリーで
■モックで確認できれば早い
ヒアリング>ワイヤーフレーム>ペーパープロトタイプ>モックアップ>プロトタイプ>スクラム/WF
ウォーターフォール的かどうかは下記2点で
ドキュメントはどのレベルでいるか?
区切り、レビューをどうするか?
DOAデータオリエンティッドアプローチからモックやADDに
https://qiita.com/masaki_u/items/2e3cb180313408b43dfe
■デッドロック
updateを避けinsertで設計をする
updateは一つのテーブルだけ、トランザクションで複数Updateを要求しない
単一のプロセスを通してだけupdate、例えば受注合計からのみ在庫更新する等で管理しやすくする
マスター更新は最後のものを採用するしか、楽観ロック
(A>Bとupdateする処理と、B>Aとupdateする処理があればデッドロックとなる)
■ヒストリテーブル
[B! SQL] 履歴テーブルから最新の1件を取ってくる方法 - そーだいなるらくがき帳
==========
■PMBOK(Project Management BodyOf Knowledge)
あるミッションのためにプロジェク卜を発足し、ミッション終了により解散するというプロフェッショナルな考え方がPMBOKの基本
プロジェクトの成功とは決められた期間と予算内に、目標どおりの効果をもたらす品質の良い成果物を出すこと
9つのエリア
1)総合管理(IntegrationManagement)
プロジェクト憲章、プロジェク卜計画書
2)スコープ管理(ScopeManagement)
どこまで作業を担当するか、成果物は何が必要か、ブラウザはChromeのみか
3)スケジュール管理(TimeManagement)
計画と監視・管理、WBS(Work Breakdown Structure)
4)コスト管理(CostManagement)
計画と監視・管理/トラッキングとコントロール、幾ら使っているか週報
5)品質管理(QualityManagement)
基準を確定するため早めに確認、後工程に不良品を流さない、品質基準書(品質を上げるために隠す事も)、テスト仕様書
6)組織管理(HumanResource Management)
体制図(開発側ユーザ側の両方)、要員の育成
7)コミュ二ケション管理(CommunicationManagement)
議事録を取り誰がいつ、共有サイト等のツール使用も、レビュー報告書、質問管理シート
8)リスク管理(RiskManagement)
問題点一覧に書き出す、ルールを定め遵守させる
9)調達管理(ProcurementManagement)
外注はRFPで、現場と現物で確認、協力会社スキル管理
5つのプロセス
立ち上げ(Initia ting) → 計画(Planning)→ 実行(Executing) → 監視・管理(Controling) → 終結(Closing)
↓
立ち上げ:PJ発足、PM選任
計画:スコープ定義、作業定義、スケジュール作成、資源管理、コスト見積、品質計画、組織計画、コミュ計画、調達計画
実行:スコープ変更、チーム構築と育成、情報の配布、進捗報告、障害報告
監視・管理:変更管理、進捗管理、コスト管理、外注管理、品質管理、リスク管理、契約管理、要員管理
終結:契約完了、PJ完了、調達終了、実績評価
最初にあるべき姿をメンバーに提示したい
PMにより総合力を高める→どうやって?
役割とマインドセットし、飴鞭のモチベーションでは(管理だけでは駄目では、特に監視されると)
職人でありスケジュール化/監視できない点がある事を認識し、自主でクリエイティブであれと、品質上後ろ向きにさせない
メンバーのスキルが低く作業が遅い、品質が悪く手戻りが多い、全体像が見えていない
教育工数積み上げ、問題点はPDCAで改善アクション
WBSをスプリントで切ってスクラムするのは?
PMBOK的資料のサンプル
http://www.shoeisha.com/book/hp/jissenpm02/27
■プロダクトオーナ
POは10年以上のベテラン推奨(幅が広く深い理解が必要=各業務に経験が必要)
POは要望を出す人でなく、第一にユーザや利害関係者からの要望を聞く人アンチパターン
プロダクトオーナーのアンチパターン | Ryuzee.com
■手法
企画(課題、べき論) > リーン開発(業務モデリング、UX、UI、データモデリング、プロジェクト管理) > 文書(要件、基本設計、詳細設計、テスト) >運用策定
開発はリーン(アジャイルでない) + PMBOK
- 計画:スコープ定義、作業定義、スケジュール作成、資源管理、コスト見積、品質計画、組織計画、コミュ二ケーション計画、調達計画
- 実行:スコープ変更、チーム構築と育成、情報の配布、進捗報告、障害報告
- 監視/管理:変更管理、進捗管理、コスト管理、品質管理、リスク管理
- 終結:PJ完了、調達終了、実績評価
※判断は客観で(ユーザ視点、セキュリティ視点)、チームでプロセス設計、コーダーが機能詳細決定
※インフラやセキュリティ: 外部IP等の設計制約
※コミュニケーション: 誰が誰と、ステークホルダ
※先に動くものを作った方が早い、改善や調整は後からで
■■設計のときに使う書籍
■業務システムのための上流工程入門(要件定義、設計)

■実践プロジェクト管理入門(PMBOK、テストのタスクはユーザの範囲だが実際は開発者が代理)

■システム設計完全ガイド(設計書を作る)

■RFP&提案書完全マニュアル

請負契約は期日までに完成品を納品することが必要
準委任なら一定の期間に労務を提供する
要件と要件を分け、何を成果物とするか、検収は誰がどう行うのか
■運用
/// BANGBOO BLOG /// - It tests you
Posted by funa : 05:38 AM | Web | Comment (0) | Trackback (0)
August 8, 2010
Make your OSXP lighter
OS WindowsXPを軽量化する
■ページングファイルを使用しない
マイコンピュータ>プロパティ>詳細設定>パフォーマンス>詳細設定>仮想メモリ>変更
リストからページングファイルがあるドライブ(ここでは「C:」)をクリックして「ページングファイルなし」
■すべてのカーネルをメモリに置きアクセスを高速化
ファイル名を指定して実行「regedit」
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SessionManager\MemoryManagement
「DisablePagingExecutive」エントリをダブルクリックして、値のデータに「1」を入力。初期値は「0」
■メモリ を最適化する
ファイル名を指定して実行「regedit」
HKEY_LOCAL_MACHINE¥SYSTEM¥CurrentControlSet¥Control¥Session Manager¥Memory Management
[IoPageLockLimit] をダブルクリック。[DWORD値の編集] ウィンドウの [表記] 項目で [10進]
[IoPageLockLimit] が見当たらない場合、ウィンドウ右の空きスペースで右クリックし [新規] → [DWORD値] で新たな値を作成。値の名前を [IoPageLockLimit] に変更する
1.初期値は128MBのメモリで設定されている。
2.入力はB(バイト)数で入力する
3.512MB搭載メモリなら「2000000~4000000」(*)が適宜。
4.1GB以上搭載メモリでも「8000000」(*)が適宜
■エラー報告は無効
「マイコンピュータ」「プロパティ」詳細設定 > エラー報告
■msconfigで自動スタートアップを停止
スタート→ファイル名を指定して実行→「msconfig」と入力して「OK」。
スタートアップタブの中から、不要なもののチェックをはずす。
■使わないスタートアップメニューを削除
スタート>すべてのプログラム>スタートアップ。
不要な項目を右クリック。表示されたメニューより「削除」をクリック。
■サービス停止
---無効----------
Error Reporting Serviceエラー時の「ご迷惑をかけて…」のメッセージ。MSに情報提供したい人以外は無効。
Fast User Switching Compatibility ユーザー切り替えを高速に行う。一人で使っている場合は必要ない。
Telephony OSインストール時のライセンス認証とダイアルアップの使用時に使われる。が、ネットワークにLAN接続している人は使わない。 無効
Remote Registry 他のPCのレジストリを操作するのに使用。セキュリティ上好ましくない機能なので無効。
---無効でOK---------
Remote Desktop Help Session Manager リモートアシスタントを利用するときに使われる。無効
Telnet Telnetサーバを提供。無効
Remote Access Auto Connection Manager プログラムがリモート DNS、NetBIOS 名または NetBIOS アドレスを参照するときに、リモート ネットワークへの接続を作成。IE以外のソフトから自動的にダイアルアップ接続をするものなので、ダイアルアップの人は手動。
---使用時以外無効---------
Routing & Remote Access Windows NTのリモート・アクセス・サービス(RAS)とネットワーク機能を統合し、さらにルーティングやパケット・フィルタリング、マルチキャスト、VPN、NAT、セキュリティなどの機能を追加
Terminal Services 他のパソコンのデスクトップを表示して操作する「ターミナル」機能を提供する
Upload Manager ネットワーク上のクライアントとサーバー間におけるファイルの同期/非同期を管理する。
NetMeeting Remote Desktop Sharing NetMeetingを使ってリモートからデスクトップにアクセス事を許可する。NetMeetingを使用しない場合無効。
Posted by funa : 08:38 AM | Gadget | Comment (0) | Trackback (0)
August 8, 2010
Re-install my OSXP
OSの再インストールする
///注意点
■他のHDDを外してOSインストール>ドライブレターが狂う
■P5BのBIOSセットアップはDELで入る>BOOTをDVDに
モニタのドライバはグラボのもの、サウンドボード/NICのドライバはマザボのものを入れる
■カートリッジのHDDをつないだら異形式として認識されて使えません>ダイナミックディスクだった事が原因
///注意点
■他のHDDを外してOSインストール>ドライブレターが狂う
■P5BのBIOSセットアップはDELで入る>BOOTをDVDに
モニタのドライバはグラボのもの、サウンドボード/NICのドライバはマザボのものを入れる
■カートリッジのHDDをつないだら異形式として認識されて使えません>ダイナミックディスクだった事が原因
- [スタート]-[ファイル名を指定して実行] から diskmgmt.msc を起動します。
- 問題のディスクを右クリックし、[形式の異なるディスクのインポート] をクリックします。
■OSのライセンス認証は電話で?
プロダクトキーのシールは本体に張られていなければならない
プリインストール用のCD?
何年も前のPCなので分からない、複数台あるし、、、
///事前手順
-デスクトップのデータを退避
-ブックマークをファイルへ出力
-FTPの設定をファイルへ出力
-メールデータをファイルへ出力、重要なもののみ個別コピー
-メールアカウントをメモ
-メール仕分けをファイルへ出力
-メールフォルダをメモ
-iPodのプレイリストをファイルへ出力、Podcastをメモ
///事後
-Ramディスクの設定
-XPの軽量化
-隠しフォルダ・拡張子の表示、フォルダ並び
-事前処理の逆
-アプリ・フォントのインストール
Posted by funa : 05:18 AM | Gadget | Comment (0) | Trackback (0)
August 7, 2010
Shooting star
■ショットサイズ アップほど強い印象
ロングショット=状況説明
フルショット
ウエストショット
バストショット
クロースアップ
ビッグクロースアップ=気持ち
■アングル
アイレベル=目高、ふつう
ローアングル=視聴者に圧力や圧迫を与える
ハイアングル=視聴者に対象の弱さを感じさせる
俯瞰=状況説明
3Feet=アイレベルより低い90cmをハリウッドでよく使う
■位置
基本は対象を真ん中に配置
配置を変えると印象が変わる
■カメラ 撮影中はズームを使わない方が良い映像になりやすい
固定カメラ=fix撮影、安心感を与える
パン=水平首フリ、広い範囲を見せる、人は左から右を見る
ティルト=上下首フリ、希望などの印象を与える
ズームイン=見せたいものへ意識の誘導
ズームアウト=緊張を緩めたり客観性を与える
ドリー=カメラの位置が変わるのでズームより強い
■編集 大きさの違うショットを組み合わせ印象を作る
インサート=映像に他の映像を挟み込みテンポや印象を作り出す
方向=向きや動きを合わせる
■音
BGM=映像動画の持つ印象を大きく変える
効果音=画面に映っていないものを表現できる
Posted by funa : 03:38 AM | Web | Comment (0) | Trackback (0)
August 5, 2010
ahe-ahe is goooood for your brain
茂木健一郎流「勉強のやり方」
(1)根拠のない自信を持て。必ずできると信じて、それを裏付ける努力をせよ。
(2)偏差値に惑わされるな。自分にとっての進歩ならば、脳内の報酬系は働いて強化学習も起こる。他人と比較しての劣等感がの一番の敵である。
(3)難易度を調整せよ。易しすぎれば、退屈する。難しすぎれば、無力感にとらわれる。自分が全力で挑戦して、やっとクリアできるような目標を立てよ。
(4)時間制限(タイムプレッシャー)をうまく使え。30分と書いてある問題があったら、自分と無理めの契約を結んで、たとえば「20分で終わらせる」と宣言してみる。そのようにして、常に最高のパフォーマンスを出すようにせよ。
(5)タイムプレッシャーは、難易度の調整にも最適である。やさしい問題をやる時にも、タイムプレッシャーをかけることで、脳にとって最適の難易度にすることができる。
(6)やろうと思ったら、1秒後にはじめよ。この番組が終わったらとか、時計の長い針が12時のところに来たらとか、まずは参考書を集めてからとか先延ばしにするな。「はっ」と気付いたら、次の瞬間に全力で走り始めろ。
(7)集中力は、生まれつきの性格などではない。集中に使われる回路は、筋肉と同じで鍛えることができる。最初はよろよろしていても、瞬間的に集中することを繰り返すことで、集中力の高い脳を作ることができる。
(8)フロー状態でせよ。最高に集中していて、しかもリラックスしている。することが、蜜の味になる。そのような内的感覚をつかみ、毎日ので実現するように心がけよ。
(9)福澤諭吉は、緒方洪庵の適塾で猛した。ある時病気になって、寝ようと思ったら枕がない。そこではっと気付いた。適塾に来て以来、しては仮眠し、目が醒めたら再び。枕を使って寝たことがなかったと。それくらいの気持ちでしてみよ。
(10)学ぶことはオープンエンド。知識は無限。入試は、目の前の試練だが、それは始まりであって終わりではない。入試をゴールと思わず、スタートラインだと思って全力で突っ切ってしまえ。そして、そのままどこかに走っていってしまえ。
スポーツだって何だって同じさフ。生でダラダラいかせて派のアハ体験
(1)根拠のない自信を持て。必ずできると信じて、それを裏付ける努力をせよ。
(2)偏差値に惑わされるな。自分にとっての進歩ならば、脳内の報酬系は働いて強化学習も起こる。他人と比較しての劣等感がの一番の敵である。
(3)難易度を調整せよ。易しすぎれば、退屈する。難しすぎれば、無力感にとらわれる。自分が全力で挑戦して、やっとクリアできるような目標を立てよ。
(4)時間制限(タイムプレッシャー)をうまく使え。30分と書いてある問題があったら、自分と無理めの契約を結んで、たとえば「20分で終わらせる」と宣言してみる。そのようにして、常に最高のパフォーマンスを出すようにせよ。
(5)タイムプレッシャーは、難易度の調整にも最適である。やさしい問題をやる時にも、タイムプレッシャーをかけることで、脳にとって最適の難易度にすることができる。
(6)やろうと思ったら、1秒後にはじめよ。この番組が終わったらとか、時計の長い針が12時のところに来たらとか、まずは参考書を集めてからとか先延ばしにするな。「はっ」と気付いたら、次の瞬間に全力で走り始めろ。
(7)集中力は、生まれつきの性格などではない。集中に使われる回路は、筋肉と同じで鍛えることができる。最初はよろよろしていても、瞬間的に集中することを繰り返すことで、集中力の高い脳を作ることができる。
(8)フロー状態でせよ。最高に集中していて、しかもリラックスしている。することが、蜜の味になる。そのような内的感覚をつかみ、毎日ので実現するように心がけよ。
(9)福澤諭吉は、緒方洪庵の適塾で猛した。ある時病気になって、寝ようと思ったら枕がない。そこではっと気付いた。適塾に来て以来、しては仮眠し、目が醒めたら再び。枕を使って寝たことがなかったと。それくらいの気持ちでしてみよ。
(10)学ぶことはオープンエンド。知識は無限。入試は、目の前の試練だが、それは始まりであって終わりではない。入試をゴールと思わず、スタートラインだと思って全力で突っ切ってしまえ。そして、そのままどこかに走っていってしまえ。
スポーツだって何だって同じさフ。生でダラダラいかせて派のアハ体験
Posted by funa : 04:48 AM | Column | Comment (0) | Trackback (0)
July 3, 2010
Rear shock OH
アジャスタボルトの低速、高速で抵抗を感じたときは締めない、緩める方向で。両方締めたらニードルが低速穴に突き刺さって折れたから。俺ルール
高速を最弱にして低速を最弱から最強まで何段あるか確かめておく、低速は最弱から調整する高速を調整するときは、低速を最弱にしてから高速を最強から弱方向へ調整する
追記
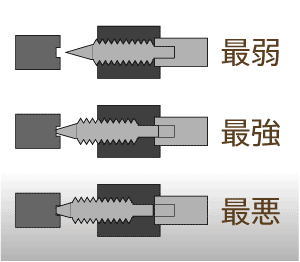 別に両方締めたからニードルが突き刺さった訳ではなさそう。低速と高速はちゃんと独立してるからだ。低速のラチェットに段数で限界がある訳でなくどこまでも回るようになっている。ニードルはネジになっていて、締めるとニードルが穴に当たり、また緩めるとニードルのオケツがベースにあたるので限界があるように感じるようになっている。つまり無理やり締めるとニードルが穴に突き刺さり段付を起こし、緩めるとニードルのねじ山が潰れてしまう。最悪になるとツマミを回しても突き刺さったままになってしまう
別に両方締めたからニードルが突き刺さった訳ではなさそう。低速と高速はちゃんと独立してるからだ。低速のラチェットに段数で限界がある訳でなくどこまでも回るようになっている。ニードルはネジになっていて、締めるとニードルが穴に当たり、また緩めるとニードルのオケツがベースにあたるので限界があるように感じるようになっている。つまり無理やり締めるとニードルが穴に突き刺さり段付を起こし、緩めるとニードルのねじ山が潰れてしまう。最悪になるとツマミを回しても突き刺さったままになってしまう→低速は極めて優しく扱う方がよく、最弱のストッパの方が安全そうだから最弱からスタートする
アジャスタボルトはOH時も外さない。
 低速用のネジが折れたのでOHする。アジャスタボルト用工具を自作。アジャスタボルトは正ネジ。 低速用のネジが折れたのでOHする。アジャスタボルト用工具を自作。アジャスタボルトは正ネジ。 |
 真ん中が低速用。周りが高速用。低速は常時隙間があるが、高速側は通常シムで塞がっている。 真ん中が低速用。周りが高速用。低速は常時隙間があるが、高速側は通常シムで塞がっている。 |
 サブタンクに続く穴が4つある。 |
 パカッと2つに割れる。左がアジャスタ部、右がバルブ部。低速穴の大きさをニードルが調節する。バネが高速用の穴をシムで押さえている。故障でニードルが段付を起こしている。 パカッと2つに割れる。左がアジャスタ部、右がバルブ部。低速穴の大きさをニードルが調節する。バネが高速用の穴をシムで押さえている。故障でニードルが段付を起こしている。 |
 サブタンクへの穴を見よ。ここからエア抜きするのが難しいのが分かる。また最後にアジャスタボルトを入れる時にエアが入らない訳がない。 サブタンクへの穴を見よ。ここからエア抜きするのが難しいのが分かる。また最後にアジャスタボルトを入れる時にエアが入らない訳がない。 |
 長さが一緒。ロッド分のオイルは全てこのアジャスタボルトの低速か高速の穴を通りピストン側からサブタンク側へ移動する。 長さが一緒。ロッド分のオイルは全てこのアジャスタボルトの低速か高速の穴を通りピストン側からサブタンク側へ移動する。 |
 アジャスタボルトを入れ、穴を出した図。 アジャスタボルトを入れ、穴を出した図。 |
 高速の14mmは逆ネジ。緩めることで中のネジを締め込みプリロードを抜く。 高速の14mmは逆ネジ。緩めることで中のネジを締め込みプリロードを抜く。 | |
 高速を締め込むことで中のネジを緩めプリロードを掛ける。 高速を締め込むことで中のネジを緩めプリロードを掛ける。 |
 故障で低速ニードルが段付を起こしているが、真ん中の穴との距離で低速を設定している。穴が小さく塞ぐ可能性がある位に繊細な設定。 故障で低速ニードルが段付を起こしているが、真ん中の穴との距離で低速を設定している。穴が小さく塞ぐ可能性がある位に繊細な設定。 |
 高速のシムはカラーを挟んでバネで強度が調節される。 高速のシムはカラーを挟んでバネで強度が調節される。 |
 アジャスタボルトの高速用のシム。 アジャスタボルトの高速用のシム。 |
 ピストン本体。シムの設定が確認できる。圧はピストンのシムを通して、伸びはピストンのシムと一方通行のオリフィスでオイルは行き来する。常時開いている穴は無い。 ピストン本体。シムの設定が確認できる。圧はピストンのシムを通して、伸びはピストンのシムと一方通行のオリフィスでオイルは行き来する。常時開いている穴は無い。 |
 リバルブ後、オリフィスは一枚のシムにより一方通行になっている。天辺のネジは外さない。ロックナットは締めが固め正ネジ。カシメは無かった。 リバルブ後、オリフィスは一枚のシムにより一方通行になっている。天辺のネジは外さない。ロックナットは締めが固め正ネジ。カシメは無かった。 |
Posted by funa : 07:08 PM | Gadget | Comment (0) | Trackback (0)
June 19, 2010
Tee
自分のサイズが分かればネットでも買える。自分なりのサイズ感を。
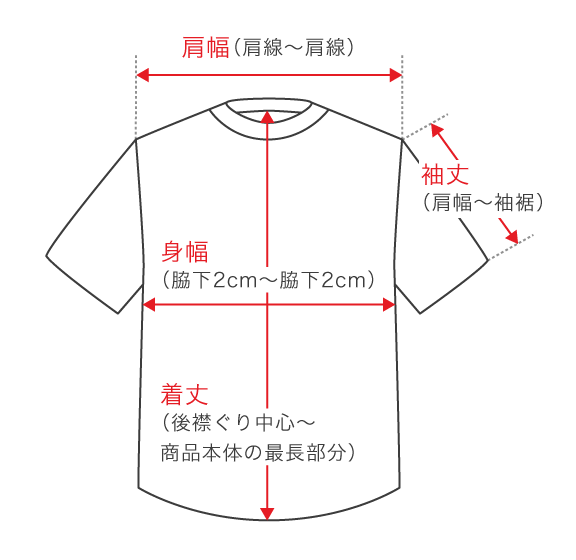
肩幅:肩の縫い目からもう片方の肩の縫い目まで
身幅:脇下から脇下まで、バストの半分
着丈:エリからスソまで
左手 人:17 中:17 薬:14 子:7
右手 人:19 中:19 薬:15 子:8
オリジナルデザインや刻印もできる
https://yubiwaring.com/ring-kokuin-692
タグ:Tシャツ Size 指輪
肩幅:肩の縫い目からもう片方の肩の縫い目まで
身幅:脇下から脇下まで、バストの半分
着丈:エリからスソまで
■タイト JP-M
肩幅 約41cm 身幅 約43cm 着丈 約60cm
■ジャスト US-M
肩幅 約47cm 身幅 約48cm 着丈 約62cm
■ゆったり US-M
肩幅 約50cm 身幅 約52cm 着丈 約66cm
■オーバサイズ US-XL
肩幅 約57cm 身幅 約57cm 着丈 約70cm
■頭 約59cm
///パンツ
チノパン w79 L76(痩せたらw76)アンクルよりジャストのL76がいい
///Ring
|
|
左手 人:17 中:17 薬:14 子:7
右手 人:19 中:19 薬:15 子:8
オリジナルデザインや刻印もできる
https://yubiwaring.com/ring-kokuin-692
タグ:Tシャツ Size 指輪
Posted by funa : 08:47 PM | Gadget | Comment (0) | Trackback (0)
June 10, 2010
SONY デジタルカメラ Cybershot HX5V
ソニー HX5V について
近くのものは割りに綺麗に映る、手ブレも慣れればもっとマシ。これは一発目だから。でもまぁそれなりだ。
動画ならビデオカメラ(60p)、画質ならDSLR(良いレンズ)が要ると思った。
室内静止画ではSCN(シーン)>高ISOがいいかも
Posted by funa : 12:22 AM | Gadget | Comment (0) | Trackback (0)
May 13, 2010
Fork OH
 秘密兵器、ペットボトルのオイルパン。上部を切ってフォークが丁度入るサイズになっている。逆さにしてフォークをはめ、ひっくり返してオイルを抜く。オイルがまったくこぼれないので超超超便利、超超超便利。チョベリンベ。
秘密兵器、ペットボトルのオイルパン。上部を切ってフォークが丁度入るサイズになっている。逆さにしてフォークをはめ、ひっくり返してオイルを抜く。オイルがまったくこぼれないので超超超便利、超超超便利。チョベリンベ。
アウターはこのペットボトルに溜めた上澄みのオイルを使いまわす。スーパー経済的、アイムスーパーパンプド(笑)!!!エコノミックアニマル。外側なので問題ないッショ。ダンパーピストンだけ新しいオイルを使う180mlx2本。
ボトムのボルトを外すとき、タイダウンで縮めると楽。シリンダユニットを挿入するときは、ロッドを一杯に延ばした状態で静かに入れる。フロントタイヤは両手で入れ足で抑えたところ、おっとり刀でアクスルを用意して入れる。両手がミソ。
アイムソースーパーパンプド(笑)!!! 上2本:ソフト、下:スタンダード。巻き数が違う。切り欠きがソフト3本、STDに2本ついていた。STDの重さが1.1kg、ソフトが1.2kg。鉄の比重7.85を当てはめるとソフトは12.7cc容量が多い。→標準フォークオイルレベルSTD361cc/ソフト348cc
上2本:ソフト、下:スタンダード。巻き数が違う。切り欠きがソフト3本、STDに2本ついていた。STDの重さが1.1kg、ソフトが1.2kg。鉄の比重7.85を当てはめるとソフトは12.7cc容量が多い。→標準フォークオイルレベルSTD361cc/ソフト348cc
レヂボンエースゴールドⅡRA-GⅡ ●砥材: A/WA ●厚さ(mm): 6 ●硬度: P
http://www.monotaro.com/g/00013671/
砥粒の種類を表し、Aは褐色アルミナ砥粒(アランダム)、A/WAは褐色アルミナ砥粒と白色アルミナ砥粒(ホワイトアランダム)の混合砥石で、共に一般鋼用です。
A/WAはAより研削性能をあげるためにWAを 混合させている砥石で、一般鋼用でより研削力を重視する場合はAではなくA/WAの砥石をお選びください。なお、WAだけの砥石はステンレス用です
オフセット砥石には硬度があり、A ~Zで表されます。標準硬度はPで、Aに近くなるほど軟らかく、Zに近くなるほど硬くなります。
通常はP(またはQ)をご使用いただき、減りは速くても いいから切れ味を優先する場合は軟かい硬度を、耐久性を重視する場合には硬い硬度をお選びください
粒度が小さいほど、砥粒は大きく、その仕上がり面は粗くなります。また粒度が大きくなれば、砥粒は小さくその仕上がり面はなめらかになります。
目安としては#24・36が重研削および研削用。#46~100が軽研削、研磨用、#120~が研磨、仕上用となります
Posted by funa : 06:45 PM | Gadget | Comment (0) | Trackback (0)





- 竹書房 Timeless on Jan 01
- Ting on Nov 09
- 空(出た~) on Oct 21
- バカ on Aug 10
- え、待って on May 06
| < January 2026 > | ||||||
| Sun | Mon | Tue | Wed | Thi | Fri | Sat |
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- January 2026
- November 2025
- October 2025
- August 2025
- May 2025
- April 2025
- February 2025
- January 2025
- December 2024
- September 2024
- August 2024
- July 2024
- June 2024
- May 2024
- April 2024
- March 2024
- February 2024
- January 2024
- December 2023
- October 2023
- June 2023
- May 2023
- April 2023
- March 2023
- February 2023
- January 2023
- September 2022
- July 2022
- May 2022
- April 2022
- March 2022
- February 2022
- January 2022
- December 2021
- June 2021
- May 2021
- Photo Boo
- デスクトップ通知スケジューラー
- オフライン予約システム
- オフライン予約システム(trancate)
- マラソンペース計算アプリ
- 時給計算アプリ
- ホワイトボード
- Tool(Winパス生成)
- AMAモトクロスマニアッX
- BANGBOOマップ
- えいごたん.jp
- Is This English???
- 無料でセキュリティカメラを設置する
- TOKIO Shock Exchange
- LPIC レベル100
- ICTIL (ITIL)
- DISCO (シスコCCNA)
- Java Lot (Java)
- Jクエネー(jQuery)
- メディアトレーニング
- Hiphop From TV
- BANGBOOナレッジマネジメント
- BANGBOOビジネスカード
