August 26, 2010
今夜はKick it (WSH a.k.a VBscript)
動きゃ良い。周辺処理とバッチをキックするWinシェル。拡張子.vbs
Dim thisFileName
Dim objShell
Dim batFile
'■バッチ実行--ファイル名取得
'■拡張子の削除
regEx.Pattern = regExDel
'■ファイル名の削除
tempText = inFile.ReadAll
'■旧リストファイルを削除
'■新リストファイルを本ファイルにリネーム
If Err.Number = 0 Then
Set fso = Nothinghttp://blog.bangboo.com/page_289.html
Posted by funa : 04:18 AM
| Web
| Comment (0) Trackback (0)
August 26, 2010
Who's BAT? (Batch file)
コマンドプロンプトcmd.exeでバッチファイルを作成。拡張子.bat
set TARGET_DIR1=F:\songs
set CURRENT_DIR=%CD%
cd /d %TARGET_DIR1%
echo 終了http://blog.bangboo.com/page_290.html
Posted by funa : 12:31 AM
| Web
| Comment (0) Trackback (0)
August 25, 2010
After Effects
Posted by funa : 05:30 PM
| Web
| Comment (0) Trackback (0)
August 18, 2010
Server transfer
xrea+からcore miniへ移行したhttps://www.value-domain.com/howto/?action=coresv_web&noheader=1
2)データ移動
4)DNS設定(ドメインをお持ちの場合)
5)ドメインウェブ設定削除(ドメインをお持ちの場合)
<IfModule mod_headers.c>
--503/503.php
///////////////oがoldでnがnewhttp://www.newdomain.com/$1 [R=301,L]http://www.newdomain.com/ http://www.exsample.com/2009/New/ http://www.multiburst.net/project-multiburst/archives/2006/01/21/1559.php
# バックアップを置くディレクトリ
# MySQLのダンプ処理(とりあえず一時ファイルとして保存)
# タイムスタンプの取得
bkfile=$dest/$timestamp.tar.gz
tar zcvf $bkfile $srcfile
if [ $? != 0 -o ! -e $bkfile ]; then
rmfile=$dest/$old_date.tar.gz
if [ -e $rmfile ]; then
rm -f /virtual/myid/db-backup/tmp
exit
Posted by funa : 05:05 PM
| Web
| Comment (0) Trackback (0)
August 18, 2010
Tools - free icon etc
Posted by funa : 04:37 PM
| Web
| Comment (0) Trackback (0)
August 9, 2010
ER
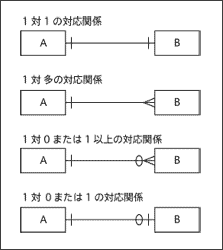
ERダイヤグラムの作図ルールのまとめ。ER図 ■要件定義
https://qiita.com/Saku731/items/741fcf0f40dd989ee4f8 発注者に満足感があり、下流で滞りなく開発ができソフトウェアが納品されればいい
色んな考え方ややり方があるので臨機応変に、どこまでが範囲か確認できればいいが
■設計者から開発者に渡すっぽい上流工程
///Why:システム開発の目的(要望)
現状の課題
ゴール(本来あるべき状態)
現状とゴールのギャップ(解決すべき課題)
///What:何をもって課題を解決するのか
システム導入後の業務フロー
機能要件
システムに実装する機能一覧
非機能要件
処理スピード、セキュリティ など様々
///How:具体的な使い勝手と実装方法(システム設計)
基本設計
画面設計(UI設計)
機能設計
データ設計
詳細設計
クラス図、シーケンス図
システムアーキテクチャ
各部位を実装する技術 など様々
■ビジネスと開発の両側で合意を取るっぽい上流工程
///要望:解決すべき課題(発注者タスク)
現状の課題
ゴール(本来あるべき状態)
現状とゴールのギャップ(解決すべき課題)
///要求:システムに実装したい機能(発注者タスク)
企画の背景(解決すべき課題)
課題解決に必要なシステムの概要
具体的に実装したい機能一覧
///検討:要求の実現性を考える(開発者タスク)
技術的に開発可能か?
予算はどの程度必要か?
納期はいつ頃になるか?
///提案:検討した結果を発注者に戻す(開発者タスク)
実装できる機能
請求する金額
納品できる期日
///要件:双方が合意した決定事項(発注者・開発者が協議して決める)
システムに実装する機能一覧
納期、請求額の目安が記載されるケースも
==========
■階層化されたシステム要件一覧(要件ツリー)の例
利益管理の強化に貢献すること
月中であっても利益ベースでの予実達成状況を監視できること
受注単位で粗利がわかるようになること
顧客サービスの改善に貢献すること
受注時に納期回答できるようであること
入荷かう出荷までロットをトレースできること
在庫管理レベルの向上に貢献すること
余剰在庫や死蔵品を50%削減できること
在庫データには常に現在の在庫状況が反映されていること
作業効率の向上に貢献すること
バーコードラベルによって入出荷作業が簡便化されているとと
配車計画をある程度自動化できること
■機能要件一覧の例
"利用者は全支店の営業部門の所属者とする。(支店は全国27箇所)"
担当者毎に、参照、登録・更新・削除、承認の権限が付与できること。
承認者が不在の場合に代理承認できること。
"パソコンだけでなく、スマートフォンからでも操作が可能なこと。(ブラウザ利用)"
過去の案件を検索できること
画面に一覧表示した内容をCSVファイルでダウンロードできること
過去の案件をコピーして新しい案件が作成できること
進捗の途中で、異動や退職によって離任する人がいた場合でも、承認者の変更ができること。
進捗の途中で、組織が変更になった際に、承認ルートの再設定ができること。
組織を兼務する利用者に対応できること。
承認や差し戻しをした際、次の担当者にメールが発信されること。
ユーザーとパスワードによるログイン機能があること
ユーザーの照会、登録、更新、削除が可能なこと
etc.
■非機能要件一覧の例
サービス停止後、再開までの時間:2時間未満。事前に業務調整をした上であれば2時間程度は許容できる。
バックアップデータの復旧時点:障害発生時点。
データ復旧までの時間:1営業日以内。急ぎの申請はメールや電話ベースで対応可能。
同時に利用されるユーザ数:1%程度と想定。10名。
ログの保管期間:2週間
特に応答速度が求められる操作および速度:5秒以内の表示。
通常の運用時間:朝6時〜夜22時までをシステム稼働時間とする。
バックアップの保存期間:次回バックアップ取得まで登録データ:3年
計画停止の有無:不定期に実施。実施する際は関係者の合意を得る。
移行作業完了後の3ヶ月間は初期稼働確認期間とし4ヶ月目からを本稼働とする。
ウィルス定義ファイルは自動更新とする。
etc.
==========
■工程を4つ程度に分けてしまう
1)上流工程(要件定義、基本設計、現状分析)
2)下流工程(詳細設計、実装、テスト)
3)ネットワーク設計・管理
4)プロジェクト管理
上流工程での注意
業務モデリング、データモデリング、機能モデリングを念頭に要件定義
要件定義するまえにPDCA調査もあり(営業を省略したいが本当に良いのかどうか)
基本設計書は拡散思考/自由発想で作っても良い
旧態依然になりがちな点に注意(先進、業務改善、便益を入れる)
基本設計書には全体像、画面、運用、セキュリティは特に担当者が知りたいことを盛る
要件と設計書の対応関係、WhatとHowは必須だがWhyもあった方が開発者も分かり易い
行間は読まれない、さりとて資料は把握はし易い方がいい
時間は23:59までか定時終了18:00までか等データは細かく確認
モックがあれば解決?
非機能要件について
http://www.aimc.co.jp/blog/p-4283/ テクニカルレビューは関係のない他の技術者に確認し妥当性を問う、ユーザ希望なのでとは言わない事
↓↓↓↓↓↓
■上流工程での成果物
-要件定義書
要望を箇条書き
前提となるハードやNWや業務フローを添付
-システム方式設計書(性能、信頼性、保守・運用、セキュリティを含む)
非機能要件一覧 (
https://pm-rasinban.com/kinou-hikinou にサンプル有)
ユースケースシナリオ
システム構成図
-画面設計(機能、アクション、遷移)
ワイヤフレーム/モック/プロトタイプ
-データ設計(項目、ドメイン定義、制約、値域、コード仕様、ネーミング、データモデルER)
細かな所まで詰める(値段変動、合計値の格納)
-業務プロセス設計
業務フローと担当部署用の業務モデル
-既存システム調査報告書
-プロジェクト計画書
※業務フローと各担当部署用の業務モデル、データモデル、機能モデルがあれば納得感はある
■下流工程での成果物
-システム詳細設計書
プログラム仕様書、DBテーブル定義、ミドルウェアパラメータ?、業務マニュアル
==========
■システム化のときに考慮すべき要素
コンピュータの五大機能:入力/出力/記憶/演算/制御(CPU/MB)→入力/出力/記憶/演算の4つでいいかも
オフィスオートメーション(紙の作業を電子化):PCやFAX等の導入で書類作成/保存/検索/送付などの事務を合理化/自動化した
インターネット化、マーケティングオートメーション、メール化、電子マネー化、AIロボット化
処理を早く多く自動で簡単にメンテフリーで
■モックで確認できれば早い
ヒアリング>ワイヤーフレーム>ペーパープロトタイプ>モックアップ>プロトタイプ>スクラム/WF
ウォーターフォール的かどうかは下記2点で
ドキュメントはどのレベルでいるか?
区切り、レビューをどうするか?
DOAデータオリエンティッドアプローチからモックやADDに
https://qiita.com/masaki_u/items/2e3cb180313408b43dfe
■デッドロック
updateを避けinsertで設計をする
updateは一つのテーブルだけ、トランザクションで複数Updateを要求しない
単一のプロセスを通してだけupdate、例えば受注合計からのみ在庫更新する等で管理しやすくする
マスター更新は最後のものを採用するしか、楽観ロック
(A>Bとupdateする処理と、B>Aとupdateする処理があればデッドロックとなる)
■ヒストリテーブル
[B! SQL] 履歴テーブルから最新の1件を取ってくる方法 - そーだいなるらくがき帳 ==========
■PMBOK(Project Management BodyOf Knowledge)
あるミッションのためにプロジェク卜を発足し、ミッション終了により解散するというプロフェッショナルな考え方がPMBOKの基本
プロジェクトの成功とは決められた期間と予算内に、目標どおりの効果をもたらす品質の良い成果物を出すこと
9つのエリア
1)総合管理(IntegrationManagement)
プロジェクト憲章、プロジェク卜計画書
2)スコープ管理(ScopeManagement)
どこまで作業を担当するか、成果物は何が必要か、ブラウザはChromeのみか
3)スケジュール管理(TimeManagement)
計画と監視・管理、WBS(Work Breakdown Structure)
4)コスト管理(CostManagement)
計画と監視・管理/トラッキングとコントロール、幾ら使っているか週報
5)品質管理(QualityManagement)
基準を確定するため早めに確認、後工程に不良品を流さない、品質基準書(品質を上げるために隠す事も)、テスト仕様書
6)組織管理(HumanResource Management)
体制図(開発側ユーザ側の両方)、要員の育成
7)コミュ二ケション管理(CommunicationManagement)
議事録を取り誰がいつ、共有サイト等のツール使用も、レビュー報告書、質問管理シート
8)リスク管理(RiskManagement)
問題点一覧に書き出す、ルールを定め遵守させる
9)調達管理(ProcurementManagement)
外注はRFPで、現場と現物で確認、協力会社スキル管理
5つのプロセス
立ち上げ(Initia ting) → 計画(Planning)→ 実行(Executing) → 監視・管理(Controling) → 終結(Closing)
↓
立ち上げ:PJ発足、PM選任
計画:スコープ定義、作業定義、スケジュール作成、資源管理、コスト見積、品質計画、組織計画、コミュ計画、調達計画
実行:スコープ変更、チーム構築と育成、情報の配布、進捗報告、障害報告
監視・管理:変更管理、進捗管理、コスト管理、外注管理、品質管理、リスク管理、契約管理、要員管理
終結:契約完了、PJ完了、調達終了、実績評価
最初にあるべき姿をメンバーに提示したい
PMにより総合力を高める→どうやって?
役割とマインドセットし、飴鞭のモチベーションでは(管理だけでは駄目では、特に監視されると)
職人でありスケジュール化/監視できない点がある事を認識し、自主でクリエイティブであれと、品質上後ろ向きにさせない
メンバーのスキルが低く作業が遅い、品質が悪く手戻りが多い、全体像が見えていない
教育工数積み上げ、問題点はPDCAで改善アクション
WBSをスプリントで切ってスクラムするのは?
PMBOK的資料のサンプル
http://www.shoeisha.com/book/hp/jissenpm02/27 ■プロダクトオーナ
POは10年以上のベテラン推奨(幅が広く深い理解が必要=各業務に経験が必要)
POは要望を出す人でなく、第一にユーザや利害関係者からの要望を聞く人アンチパターン
プロダクトオーナーのアンチパターン | Ryuzee.com ■手法
企画(課題、べき論) > リーン開発(業務モデリング、UX、UI、データモデリング、プロジェクト管理) > 文書(要件、基本設計、詳細設計、テスト) >運用策定
開発はリーン(アジャイルでない) + PMBOK
- 計画:スコープ定義、作業定義、スケジュール作成、資源管理、コスト見積、品質計画、組織計画、コミュ二ケーション計画、調達計画
- 実行:スコープ変更、チーム構築と育成、情報の配布、進捗報告、障害報告
- 監視/管理:変更管理、進捗管理、コスト管理、品質管理、リスク管理
- 終結:PJ完了、調達終了、実績評価
※判断は客観で(ユーザ視点、セキュリティ視点)、チームでプロセス設計、コーダーが機能詳細決定
※インフラやセキュリティ: 外部IP等の設計制約
※コミュニケーション: 誰が誰と、ステークホルダ
※先に動くものを作った方が早い、改善や調整は後からで
■■設計のときに使う書籍
■業務システムのための上流工程入門(要件定義、設計)
■実践プロジェクト管理入門(PMBOK、テストのタスクはユーザの範囲だが実際は開発者が代理)
■システム設計完全ガイド(設計書を作る)
■RFP&提案書完全マニュアル
請負契約は期日までに完成品を納品することが必要
準委任なら一定の期間に労務を提供する
要件と要件を分け、何を成果物とするか、検収は誰がどう行うのか
■運用
/// BANGBOO BLOG /// - It tests you Posted by funa : 05:38 AM
| Web
| Comment (0) Trackback (0)
August 7, 2010
Shooting star
■ショットサイズ アップほど強い印象
http://www.youtube.com/watch?v=puGVyFKxyt0
Posted by funa : 03:38 AM
| Web
| Comment (0) Trackback (0)
May 7, 2010
Even small things can't kill me
■フォームへHTML特殊文字を表示する
これはフォームの動作なので仕方がないが、フォームの送信は表示したものを送るようになっているので、DBにエスケープして入れていた文字が、いつのまにか文字化けを起こしたりすることになる。
つまり、DBから「<」などエスケープされたHTML文字をtextareaに表示するときは、事前に「&lt;」などに変換しておく必要がある。
一度「®」を「マルR」と表示したものを送信し直しても特に問題は起こらないとすると以下の4つの処理をしておけば良い事になる。
$ent = str_replace("&", "&amp;", $ent);
Posted by funa : 01:08 AM
| Web
| Comment (0) Trackback (0)
April 24, 2010
Adobe Premire6.0 (Guru R.I.P.)
- スローモーション 全日本選手権モトクロス第2戦関東
■Premire6.0
■撮影
Posted by funa : 01:42 AM
| Web
| Comment (0) Trackback (0)
April 23, 2010
jQuery - write less, do more.
-
Jクエネー write less, homeless jQueryについてのまとめサイト。プラグインのリファレンスやサンプルでなく、AJAXや
メソッドチェーンでJavaScriptを書いていくやり方を覚えられるようにしたつもり。速習、入門。
///////Javascript メモ///////
var a = document.getElementById('hoge').value;
<input type="text" name="hoge" id="hoge">
name="hoge" でIEは認識するが、Firefoxでは認識しない。Firefoxでは id="hoge"も入れる
Posted by funa : 06:09 AM
| Web
| Comment (0) Trackback (0)