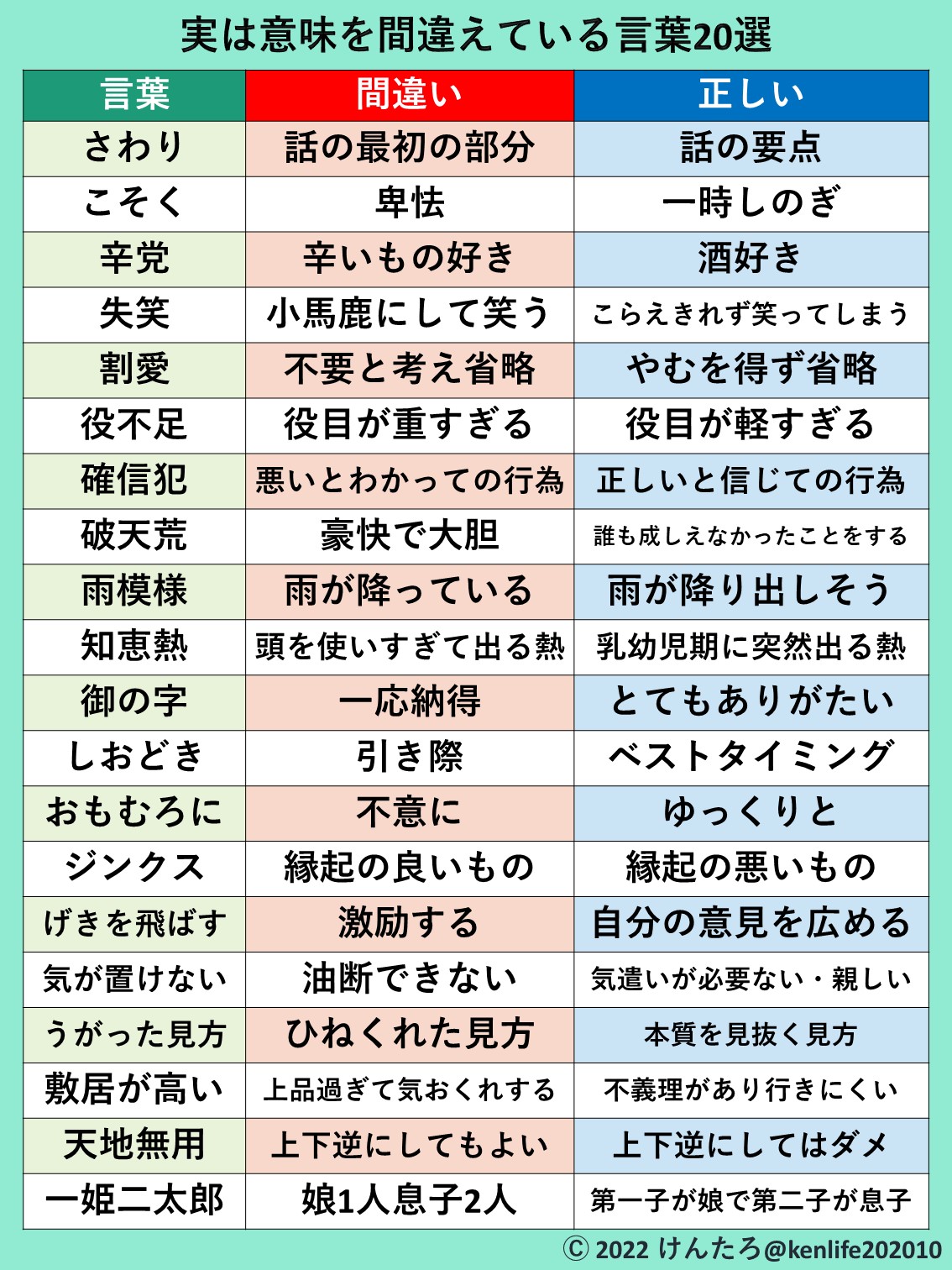
機械学習:
マシーンラーニング、ML。マッシーンがLearnしデータの背景にあるルールやパターンを発見する。
モデル:
機械学習における入力データに対して結果(出力)を導き出す仕組み。モデルは入力されたデータを解析し、評価/判定を行った結果を出力として返す。つまり、機械学習は「入カ>モデル>出力」から成る。
学習データ
モデルをつくるために学習させるデータ
適用データ
モデルに対して予測を適用させるデータ
教師あり
学習データに対して正解ラベルを付けて学習する方法
例)過去にDMを送付した結果(目的変数)を用いて学習させる
教師ありは、回帰と分類の2つに分けられます。
回帰(予测)
連続する数値を予測するもので、売上、重量、温度などを算出する
分類(識別)
データがどのクラスに属するかを予測するもので、販売商品が売れる見込み/売れない見込みなどに分類
DMにおいては分類モデル(買う・買わないの識別)を使用
目的変数
結果側の変数
例)ある特定のカテゴリやブランドをその顧客が注文する
●確率(購入する・しない)
ー学習データにターゲットフラグ (購入あり=1、購入無し=0)を立てる
ー適用後に出てくる結果は0~1 (0%~100%) の範囲
●金額
説明変数(特微量とも呼ぶ)
原因側のデータ
目的変数を予測するために使用する顧客の様々な情報、大きく分けて2種類
●顧客属性
ー法人/個人事業主など事業形態、登録住所の郵便番号、業種コードなど
●購買履歴
ー購買 いつ、何を、どのくらい購入したか等の情報
ー各商品カテゴリ毎の購入金額 etc.
質的変数
数値で推し測ることができ、数字の大小に意味をもつデータ
(例)売上、購入回数、従業員数、DM送付回数
單的変数
単に分類や種類を区別するためだけのデータ
(例)都道府県、茎種コード、購入有無
統計手法
重回帰分析:
説明変数xが目的変数yの値を変化させます。そのため、説明変数から、目的変数の値を予測可能です。
ロジスティック回帰
yが1になる確率を判別します。いくつかの要因(説明変数)から「2値の結果(目的変数)」が起こる確率を説明・予測
2値の結果とは合格/不合格、採用/不採用など、答えが2つしかない場合を指し
線形回帰(エクセル)
slope関数:回帰直線の傾きを取得
inercept関数:回帰直線の切片を取得
forecast関数:単回帰分析からの推測値を取得
+++++++++++++
線形回帰(エクセル)
slope関数:回帰直線の傾きを取得
inercept関数:回帰直線の切片を取得
forecast関数:単回帰分析からの推測値を取得
+++++++++++++
BigQueryを利用して機械学習を簡易に学びたいです。Webアプリのログよりサーバーエラーを予測するようなもので方法を教えてください > BigQueryを利用して機械学習を学び、Webアプリのログからサーバーエラーを予測する方法について簡単に解説します。以下はその手順の概要です。
●ステップ1: データの準備
まず、WebアプリのログデータをBigQueryにインポートします。ログデータには、タイムスタンプ、リクエストの詳細、ステータスコード、エラー メッセージなどの情報が含まれているはずです。
例:ログデータスキーマ server_log
timestamp: TIMESTAMP
request_id: STRING
status_code: INTEGER
error_message: STRING
user_agent: STRING
response_time: FLOAT
●ステップ2:データの前処理
エラーログの解析を容易にするために、データをクリーンアップし、特徴量を作成します。
CREATE OR REPLACE TABLE ds.cleaned_log AS
SELECT
timestamp,
status_code,
error_message,
user_agent,
response_time,
IF(status_code >= 500, 1, 0) AS is_error
FROM
ds.server_log
WHERE
timestamp BETWEEN 2023-01-01 AND 2023-12-31;
このクエリでは、ステータスコードが500以上のものをエラーと見なし、is_error列を追加しています。
●ステップ3:特徴量エンジニアリング
機械学習モデルに投入するための特徴量を作成します。例えば、以下のような特徴量を考えます。
-時間帯 (hour)
-ユーザーエージェント (user_agent)
-過去のエラーレート(past_error_rate)
※past_error_rateを省くとどうなのか?
CREATE OR REPLACE TABLE ds.features AS
SELECT
EXTRACT(HOUR FROM timestamp) AS hour,
user_agent,
response_time,
is_error,
--AVG(is_error) OVER (PARTITION BY user_agent ORDER BY timestamp RANGE BETWEEN INTERVAL 1 DAY PRECEDING AND CURRENT ROW) AS past_error_rate
AVG(is_error) OVER (PARTITION BY user_agent) AS past_error_rate
FROM
ds.cleaned_log;
●ステップ4: 機械学習モデルの作成
BigQuery MLを使用してモデルを作成します。ここではロジスティック回帰モデルを使用してエラーの予測を行います。
他には、The CREATE MODEL statement | BigQuery | Google Cloud
他には、The CREATE MODEL statement | BigQuery | Google Cloud
MODEL_TYPE = { 'LINEAR_REG' |'LOGISTIC_REG' |'KMEANS' |'MATRIX_FACTORIZATION' |'PCA' |'AUTOENCODER' |'AUTOML_CLASSIFIER' |'AUTOML_REGRESSOR' |'BOOSTED_TREE_CLASSIFIER' |'BOOSTED_TREE_REGRESSOR' |'RANDOM_FOREST_CLASSIFIER' |'RANDOM_FOREST_REGRESSOR' |'DNN_CLASSIFIER' |'DNN_REGRESSOR' |'DNN_LINEAR_COMBINED_CLASSIFIER' | 'DNN_LINEAR_COMBINED_REGRESSOR' |'ARIMA_PLUS' |'ARIMA_PLUS_XREG' |'TENSORFLOW' |'TENSORFLOW_LITE' |'ONNX' |'XGBOOST'}
CREATE OR REPLACE MODEL ds.error_prediction_model
OPTIONS(model_type='logistic_reg', input_label_cols=['is error'] AS
SELECT
hour,
user_agent,
response_time,
past_error_rate,
is_error
FROM
ds.features;
●ステップ5: モデルの評価
モデルを評価し、精度を確認します。
SELECT
*
FROM
ML.EVALUATE(MODEL, `ds.error.prediction_model`,(
SELECT hour,
user_agent,
response_time,
past_error_rate,
is_error
FROM
ds.features
));
●ステップ6: エラーの予測
新しいデータを使ってエラーを予測します。
SELECT
*
predicted_is_error,
predicted_is_error_probs
FROM
ML.PREDICT(MODEL `ds.error_prediction_model`,(
SELECT
EXTRACT(HOUR FROM timestamp) AS hour,
user_agent,
response_time,
--AVG(CASE WHEN status_code 500 THEN 1 ELSE 0 END) OVER (PARTITION BY user_agent ORDER BY timestamp RANGE BETWEEN INTERVAL 1 DAY PRECEDING AND CURRENT ROW) AS past_error_rate
AVG(CASE WHEN status_code >= 500 THEN 1 ELSE 0 END) OVER (PARTITION BY user_agent) AS past_error_rate
FROM
ds.new_server_log
));
●ダミーデータ
INSERT INTO ds.server_log (timestamp, request_id, status_code, error_message, user_agent, response_time)
VALUES
('2024-06-28 18:00:00 UTC', 'req 801, 208, '', 'Mozilla/5.0 (Windows NT 18.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36', 0.123),
(2024-06-20 10:01:00 UTC', 'req 002, 588, Internal Server Error', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36', 8.456),
(2024-06-28 10:02:00 UTC', 'req 003', 484, 'Not Found', 'Mozilla/5.0 (iPhone; CPU iPhone OS 14,6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Mobile/15E148 Safari/604.1, 8.234),
(2024-06-20 10:03:00 UTC', 'req 004', 200, '', 'Mozilla/5.0 (Windows NT 18.8; Win64; x64; rv:89.0) Gecko/20100181 Firefox/89.8, 0.345),
(2024-06-28 10:04:00 UTC, 'req 005', 502, Bad Gateway', 'Mozilla/5.0 (Linux; Android 11; SM-G9918) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.8.4472.124 Mobile Safari/537.36, 0.678),
(2024-86-28 10:05:00 UTC, 'req 006', 503, 'Service Unavailable', 'Mozilla/5.0 (iPad; CPU OS 14.6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Mobile/15E148 Safari/6084.1, 0.789), (2824-86-28 18:06:00 UTC, req 007, 200, Chrome/91.0.4472.124 Safari/537.36, 0.567), Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
(2024-06-2010:07:00 UTC, 'req 008, 500, Internal Server Error', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.8.4472.124 Safari/537.361, 0.890),
(2024-06-20 18:08:00 UTC, req 009, 404, Not Found', 'Mozilla/5.0 (iPhone; CPU iPhone OS 14 6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Mobile/15E148 Safari/604.11', 8.345),
('2024-06-28 18:09:00 UTC', 'req 010', 200, '', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0 Gecko/20100101 Firefox/89.0', 0.456);
INSERT INTO ds.new_server_log (timestamp, request_id, status_code, error_message, user_agent, response_time)
VALUES
(2024-06-21 09:00:00 UTC', 'req 101', 200, '', 'Mozilla/5.0 (Windows NT 18.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36', 0.112),
(2024-06-21 09:01:08 UTC, req 102', 500, Internal Server Error', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.8.4472.124 Safari/537.36, 0.478),
(2024-06-21 09:02:00 UTC', 'req 183, 484, 'Not Found', 'Mozilla/5.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Mobile/15E148 Safar1/684.1, 0.239),
(2024-06-21 09:03:00 UTC', 'req 104, 200, Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0, 8.301),
(2024-06-21 09:04:08 UTC, req 185', 502, 'Bad Gateway', 'Mozilla/5.0 (Linux; Android 11; SM-G9918) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.8.4472.124 Mobile Safari/537.36', 8.683),
(2024-06-21 09:04:08 UTC, req 185', 502, 'Bad Gateway', 'Mozilla/5.0 (Linux; Android 11; SM-G9918) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.8.4472.124 Mobile Safari/537.36', 8.683),
(2024-06-21 09:05:00 UTC, req 106', 503, Service Unavailable', 'Mozilla/5.0 (iPad; CPU OS 14,6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Mobile/15E148 Safari/604.1, 0.756),
(2024-06-21 09:06:00 UTC, req 107, 208, ", Mozilla/5.0 (Windows NT 18.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.8.4472.124 Safari/537.36, 0.523),
(2024-06-21 09:07:00 UTC, req 188, 500, Internal Server Error, Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.8.4472.124 Safari/537.36, 0.812),
(2024-06-21 09:06:00 UTC, req 107, 208, ", Mozilla/5.0 (Windows NT 18.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.8.4472.124 Safari/537.36, 0.523),
(2024-06-21 09:07:00 UTC, req 188, 500, Internal Server Error, Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.8.4472.124 Safari/537.36, 0.812),
('2024-06-21 09:08:08 UTC', 'req 109,, 404, 'Not Found', 'Mozilla/5.0 (iPhone: CPU iPhone OS 14,6 1ike Mac OS X) AppleWebKit/685.1.15 (KHTML, like Gecko) Version/14.1.1 Mobile/15E148 Safari/604.1', 0.267),
('2024-06-21 09:09:08 UTC', 'req 110', 200, '', 'Mozilla/5.0 (Windows NT 18.8; Win64: x64; rv:89.0) Gecko/20180101 Firefox/89.8', 8.412);