December 24, 2024
He is a good egg.
ゆで卵 キン肉マン 聖なる夜 メリーXマス
茹でる前に画びょうで平ケツに穴をあける
湯に酢を入れる
7分強茹でる
余熱5分くらい(ゆで計測器で測る)
Posted by funa : 09:00 PM
| Column
| Comment (0)
| Trackback (0)
September 5, 2024
Flask
■formaction (hidden以外でのSubmit先変更方法)
buttonや inputのtype=submit/image に付与できる
ベースとなるのはformのidのformタグ<input... form="formのid">
<form id="form" method="post">
<button type="submit" formaction="app.html" name="transition" value="a" form="form">戻る</button>
<button type="submit" formaction="ok.html" name="transition" value="b" form="form">送信</button>
下記のような属性がある
formaction
formenctype
formmethod
formnovalidate
formtarget
■jinja2
///dict
my_dic['name'] = 1
return render_template('index.html', message=my_dic)
テンプレ側
{{message.name}}
///リスト
num_list = np.arange(10)
return render_template('index.html', message=num_list)
テンプレ側
{% for num in num_list %}
<div>{{ num }}</div>
{% endfor %}
///改行
{%- xxx -%} jinjaタグの前後マイナスで改行空白を除外する
+はtrim_blocks(改行詰め)、Istrip_blocks(空白詰め)を無効化する設定で俺は使わない
from jinja2 import Environment
jinja_env = Environment()
jinja_env.trim_blocks = True
jinja_env.Istrip_blocks = True
///置換
{{ "aaagh" | replace("a","oh,","2") }}
-> oh,oh,agh
{{ input['txtarea'] | replace("\n","<br />") }}
///エスケープ
safeフィルタがなければhtmlエスケープがかかる
{{ output | safe }}
あるいは
{{% autoescape False %}}{{ output }}{{% endautoescape %}}
///コメント(複数行ok)
{# note: commented-out we no longer use this
{% for user in users %}
…
#}
///生
{% raw %}
<ul>
{% for item in seq %}
<li>{{ item )}</li>
{% endfor %}
</ul>
{% endraw %}
///extend と block と include
●flask
page=page_a.model(user)
return render_template("layout.html",title=title,page=page)
●layout.html (テンプレ切替と共通ブロック、共通ブロックはテンプレに書いた方分かり易い?)
{% if page['destination']== 'confirm' %}
{% extends "template_confirm.html" %}
{% elif page['destination']== 'complete' %}
{% extends "template_complete.html" %}
{% else %}
{% extends "template_html" %}
{% endif %}
{% block body %}
{% include "header.html" %}
<p>content here.</p>
{% endblock %}
●template.html
<html>
<body>
<h1>{{ title }}</h1>
{% block body %}
{% endblock %}
#0以上の入力データの確認 (空の確認やintへのキャスト)
#{% if 'inquiry_id' in page['input'] and page['input']['inquiry_id'] is not none and page['input']['inquiry_id'][int > 0 %}
{% if page[input']['inquiry_subject'] %}
<input name="inquiry_subject" type="text" placeholder="例)a" value="{{ page['input']['inquiry_subject'] }}">
{% else %)}
<input name="inquiry subject" type="text" placeholder="例)a">
{% endif %}
{% include "footer.html" %}
</body>
</html>
●header.html
<p>date:2024-8-27</p>
●footer.html
<p>author.p</p>
●page_a.py
def model(user):
value_return = ""
input = {}
error = {}
value_return <br>under constructions taken place by user '<br>'
#入力があった、
if request.method == "POST":
transition = request form.get("transition")
#get, post, 取得するもので書き方が違う
#request.args.get("inquiry_id")
#request.form.get("inquiry_id"
#request.json.get("inquiry_id")
logging warming('#####' + user + 'transition: ' + str(transition)+'#####')
if transition == "new" or transition == "error" or transition == "confirm back":
flag_ng=0
#入力値の判定
error_txt_inquiry_subject = []
inquiry_subject = request.form.get("inquiry_subject")
ff not checkRequire(inquiry_subject):
error_txt_inquiry_subject.append("件名が空欄です”)
flag_ng=1
input[inquiry_subject] = inquiry_subject
if flag_ng == 1:
error['error_txt_inquiry_subject] = error_txt_inquiry_subject
#エラー画面を出す
destination = "error"
else:
#確認画面を出す
destination = "confirm"
#End of transition == "new" or transition == "error" or transition == "confirm back":
else:
#transition == "confirm_proceed"
#登録処理し完了画面を出す
destination = "complete"
else:
#初期画面を出す
destination = "new"
return ("value":value_return, "destination":destination, "input":input, "error":error)
■改行
プレースホルダー内での改行は
:に置き換える
<textarea placeholder="例) aaa bbb">
JINJA2のフォーム入力後の確認HTMLの改行は?
置換ではhtmlエスケープが掛かり<br>がそのまま表示されてしまいダメ
{{ input | replace("\n", "<br>") }}
htmlエスケープ(HTMLエスケープは<>&のみだった)
• 入力があればhtmlエスケープ+改行<br/>変換
• html表示はそのままhtmlエスケープ+改行<br/>変換状態で出力
• DBにそのままhtmlエスケープ+改行<br/>変換状態で出力入れる
• htmlフォーム内表示はhtmlエスケープを解除し表示
↓
入力値はそのままinput変数に保持
confirm画面でエスケープ (html.escape()+改行<br/>変換) しescape変数に保持
DB保存時にはescape変数にプラスしてダブル/シングル/バッククォート、セミコロン、バックスラッシュをエスケープし保存
DBから取り出す際はそれらをアンエスケープしescape変数に保持
Docへはinput変数で保存
画面表示時はアンエスケープ (改行<br />変換+html.unescape())
def escapeHtmlBr(text):
if text is None:
return text
elif isinstance(text, list):
list_escaped = [html.escape(item) for item in text]
list_escaped [item.replace("\n', '<br>') for item in list_escaped]
return list_escaped
else:
escaped_text = html escape(text)
return escaped_text.replace('\n', '<br>')
def unescapeHtmlBr(text):
if text is None:
return text
elif isinstance(text, list):
list_unescaped = [item.replace('<br>', '\n') for item in text]
list_unescaped = [html.unescape(item) for item in list_unescaped]
return list_unescaped
else:
text text.replace('<br>', '\n')
return html.unescape(text)
def escapeDB(text):
if text is None:
return text
elif isinstance(text, list):
list_escaped = [item.replace(';', ';') for item in text]
list_escaped = [item replace('"', '"') for item in list_escaped]
list_escaped = [item.replace("'", ''') for item in list_escaped]
list_escaped = [item.replace('\\', '\') for item in list_escaped]
list_escaped = [item.replace('`', '`') for item in list_escaped]
return list_escaped
else:
escaped_text = text.replace(';', ';')
escaped_text = escaped_text.replace('"', '"')
escaped_text = escaped_text.replace("'", ''')
escaped_text = escaped_text.replace('\\', '\')
escaped_text = escaped_text.replace('`', '`')
return escaped text
def unescapeDB(text)
if text is None
return text
elif isinstance(text, list):
list_unescaped = [item replace('`', '`') for item in text]
list_unescaped [item.replace('\','\\') for item in list_unescaped]
list_unescaped [item.replace(''', "'") for item in list_unescaped]
list_unescaped [item.replace('"', '"') for item in list_unescaped]
list_unescaped [item.replace(';', ';') for item in list_unescaped]
return list_unescaped
else:
unescaped_text = text.replace('`','`')
unescaped_text = unescaped_text.replace('\', '\\')
unescaped_text = unescaped_text.replace(''', "'")
unescaped_text unescaped_text replace('"', '"')
unescaped_text = unescaped_text.replace(';', ';')
return unescaped_text
■文字確認
def check_special_characters(a):|
#チェックする記号のセット
special_characters = ['<', '>', '"', '&']
#特定の記号が含まれているかをチェック
if any(char in a for char in special_characters):
raise ValueError(f"変数 'a' に禁止されている文字が含まれています: {a}")
try:
a = "Hello & World"
check_special_characters(a)
except ValueError as e:
print(e)
■DBのnull行の排除
bq = bigquery.Client()
sql = f"""SELECT a FROM `ds.b' WHERE c = '{pri}'"""
results=bq.query(sql)
list = list()
for row in results:
if row.a is not None:
list.append(str(row.a))
■Flask-WTF CCSRF対策でhiddenに入れる
https://qiita.com/RGS/items/c8c99970054a481ac80d
requrement.txt Flask-WTF==1.2.1
from flask_wtf import CSRFProtect
app = Flask(__name__)
app.config['SECRET_KEY'] = 'mysecretkey'
csrf = CSRFProtect(app)
<input type="hidden" name="csrf_token" value="{{ csrf_token() }}"/>
PRGパターンでGETで完了画面に行くがエラーとならない、WTFはPOSTのみ利くようだ
●完了画面でセッション変数がない場合はエラーとする
保存処理でdoc_idをセッション変数に入れ
不正で直接完了画面にいくとエラーとする
https://xxxx.com/complete?doc id=ddd
■重複登録の回避策(PRG方式+JSボタン無効)
・リダイレクト POST/Redirect/GET パターン
・連打を避けるためボタンのJS無効化
片方のみのためquerySelectorAll() を使う>ページ遷移しなくなった>下記JSを使う
@app.route('/submit', methods=['POST'])
def page():
page = model
if complete:
session['doc_id'] = page['input']['doc_id']
redirect(url_for('thank_you'))
else:
retrun template('layout.html')
@app.route('/thank_you')
def thank_you():
if 'doc_id' in session:
page['input']['doc_id"] = session['doc_id"]
session clear()
return render_template('complete_layout.html', page=page)
else:
return render_template('error.html", message="missing arg")
@app.errorhandler(404)
def page_not_found(e)
return render_template('error html', message="Page not found"), 404
error.html側
<h1>{{message }}</h1>
submit側
連打を避けるためボタンの無効化
片方のみのためquerySelectorAll() を使うとページ遷移しなくなる等がある
<script>
document.addEventListener('DOMContentLoaded', function(){
const form = document.getElementById('form');
const buttons = form.getElementsByTagName('button');
form.onsubmit= function(event) {
//クリックされたボタンを取得
const clickedButton = event.submitter;
//隠しフィールドを追加して、ボタンのname と value を送信
const hiddenField = document.createElement('input');
hiddenField type = 'hidden'
hiddenField.name = clickedButton.name;
hiddenField.value = clickedButton value;
form.appendChild(hiddenField);
// すべてのボタンを無効化して二重送信を防止
for (let i = 0; i < buttons.length; i++) {
buttons[i].disabled = true;
}
}
}
</script>
Posted by funa : 11:34 PM
| Web
| Comment (0)
| Trackback (0)
August 17, 2024
モバイルキーボードアクションカメラ
モバイルキーボード Bluetooth 3.0 Keyboard KIKIGOAL
低電圧でLED青灯、充電4hrsで60hrs使用、充電時は赤灯で完了時は消灯
Fn+C(青歯アイコン)でBluetooth灯が点滅しペアリング準備中(Bluetooth 3.0 Keyboard)
接続時に消灯、CapsLockでLED白灯
システム切換:Fn+WでWin用、Fn+QでAndオイド用、Fn+EでiOS用
AndオイドはShift+Spaceで日本語切り替え
コピペ:メール等のテキストappはカーソルがでるのでShift+←→で選択、Ctrl+c/v
ブラウザは、反転させてから後ろへはShift+→で選択できる、もっと良い方法は?
F10で英数不可問題:システムをandオイドにせず、winだとスマホの機能はFnで呼び出さない
つまり入力時はFn+WでWin用にすると良い
F6:ひらがな/F7:全角カナ/F8:半角カナ/F9:全角英数/F10:半角英数
変換問題:スペース後に早すぎる決定があると最初の候補が選ばれる?
変換時にSpaceで切替てEnter押しても変、タッチパネル使う?
↓
安価タブレットの方が読書メモには使いやすい<画面デカいし入力予測の選択がやり易い
2024/11に1万円だが、モッサリし過ぎなのでもうちょい良いのが欲しいが
タブレット BMAX I9Plus
Android14 1.8GHz 8コアCPU
ディスプレイ 10.1inches 1280x800 FHD1080p
メモリ4G+8G 64GBストレージ
bluetooth5, 802 11 acbgn, microsd
==========
アクションカメラ XTU S6 JP-S6
Ambarella H22 CPU Cortex-A53/1.2GHz 4コア
SONY IMX386、1/2.8''CMOSセンサー
170度広角、6軸ジャイロ手ぶれ補正4.0
H.264/265コーデック
Mirco SDカード クラス10UHS-3以上 64-256GB
1350mAhバッテリー
【SuperView超広角機能&縦向き撮影機能】スーパービュー機能で臨場感のある広角映像を撮影できます。4:3 のアスペクト比で撮影した映像が 16:9 のアスペクト比にダイナミックに引き伸ばされます。カメラセンサーの 4:3 比率で得られる上下幅を利用するため、カメラを水平線に向けている場合でも撮影範囲に入る空や地面が広くなる(4K/30fps,1080P/60fps)
【WiFi/リモコン/音声制御可】Wi-Fiが内蔵、スマホに専用アプリをインストールすれば、ライブビューモードで画像を確認するだけではなく、撮影した映像を動画共有サイトやSNSに直接に投稿することができます。10Mの遠隔操作ができるリモコンコントロール付。音声で録画はじめ、終了と制御出来ます
【Gyroflowアプリ対応&Type-Cポート対応&HDMI出力】手ブレを補正するジャイロデータモードが搭載されているため、手ブレ補正アプリ「Gyroflow」に対応。手ぶれ補正のレベルや画像効果を自由に編集することができます。Type-Cで高速充電可能です。さらに、MicroHDMIも搭載されているため、映像をテレビやプロジェクターなどの大画面で再生できます。USBType-Cで充電や外部マイク可。
風切り音?ケースの振動打音?が酷い、外部マイクが適さないため、吸音系の処理をしたい
当日テスト撮影してAWBとISOと明るさを決めるのが良さそう(AWB/ISOは自動で明るさだけでもいいが)
↑
■中央サイズ表示:録画設定
4K30、4K30(SuperView)、2.7K30、1440P60、1440P30、1080P120、1080P60、1080P60(SuperView)、1080P30、1080P30(SuperView)、720P240-30>720P60(か1080P60)
セグメント:自動、1/3/5分>5分
録音on/off>ON
事前記録9-20s/off>OFF
測光モード:中央重点/評価/スポット>評価
露出:+3to-3>-0.5
LDC(Lens Distortion Correction:歪曲の曲面補正)>ON
手振れ補正:オフ/普通/ジャイロデータ>スーパー補正
AWB(オートホワイトバランス):自動/晴れ/曇り/白熱灯/蛍光灯>自動(晴れ)
ISO:100-1600>自動(100から出来るだけ低め)
シーンモード:自動/人物/風景/露補正>風景
シャープネス:高/ミディアム/低>高
コントラスト:1-6>3
明るさ:1-6>2
彩度:1-6>5
画像の品質:標準/高>高
フィルタ:オリジナル/モノクロ/ビビッド/セピア/ワーム/クール>オリジナル
エンコード:H264/H265(見れんかった)>H264(mp4 低圧縮だがwinデフォで使える)
■コグアイコン:設定
自動スリープ:オフ10-60s>30
自動オフ1-5m>3m
wifi 周波数50/60Hz>50
WDR(ワイドダイナミックレンジ)逆光や白飛びや黒つぶれハードウェア処理、文字が見難くなる>ON
マイク音量:ノイズ小/デフォ/高>ノイズ小
前画面の視角(FOV:field of view)>デフォ
Flipホーム画面を90/180/270°回転>0
スタンプ(時間を記録)>ON
操作音(ボタンの押下音、シャッター音)
グリッドガイド(参照グリッド線のon/off)
日付
音声制御(ビデオスタート、ビデオ停止、スクリーンオン、スクリーンオフ、wifi on、wifi off、写真を撮る)>ON
SDフォーマット
初期設定に戻す
■絵アイコン:再生
再生一覧
■ビデオアイコン:撮影モード
撮影モード(録画、タイムラプス:静止画を定期的に撮影して繋げる、スローモーション、夜景モード、ドラレコ、録画+撮影)
※モードを選ぶと使えるサイズとFPSが決まる、手振れ補正使えないサイズもある、スローは音無し>(通常)録画
■操作:下にスワイプ
wifi on>off
画面回転
リモコン>on
音声制御>on
画面ロック
電源off
■物理ボタン
電源/撮影モードボタン
撮影開始/停止/3s長押しで前後モニター切り替えボタン
※電源と撮影開始ボタンの間に内蔵マイク穴
▲ボタン(設定メニュー、長押しwifiスイッチ)
▼ボタン(録画設定)
■リモコン
赤カメラアイコン:写真
グレービデオアイコン:動画
■撮影
カメラを装着、電源を真ん中ボタン長押しで入れ、リモコンのグレーで撮影開始、リモコンのグレーで撮影停止
ハンドルバーにセットだけで逆撮りだが撮影可
ブレが修正されており、画像も綺麗で問題ない
逆画面になっているがプレイヤーでもエディターでも回転できる
タイムラインで選択してプレビューで⊕を回転ドラッグ
自撮り棒は振動で角度が駄目になるのでフェンダー固定が必要そう
※電源が入らず2025/1に交換した v1.06>v1.08のマニュアルになった、3年保証で補償も悪くない
過充電か過放電?数回の使用で何もしてないが気を付けられるのはそこだけ
Posted by funa : 07:20 PM
| Gadget
| Comment (0)
| Trackback (0)
July 18, 2024
ノーの状態
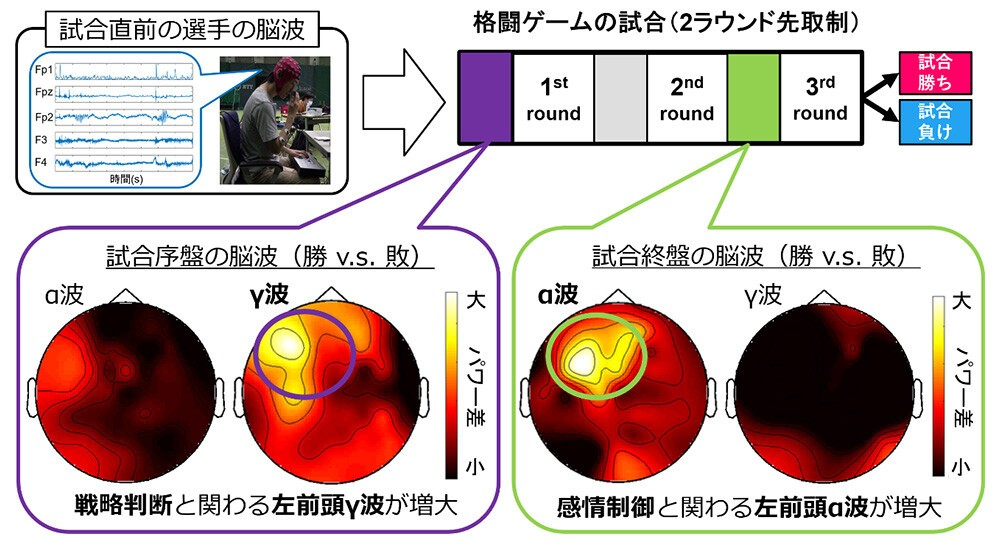
ウメハラ氏がいわゆるビーストモードで勝つ時は「強い恐怖」がきっかけと振り返りで語っていたので、きっとそうやって扁桃体や海馬辺りの「古い脳」を活性化させているのだろう
因果が逆のような気も
γ波からα波なら良いが、逆に行ってまう場合もあるやろし、イケると思ってイケないと
[B! 脳] 世界初、eスポーツ対戦直前の脳波から勝敗と強く関わるパターンを発見・実証~「実力が拮抗した試合」や「番狂わせ」を約80%の精度で予測~ | ニュースリリース | NTT (hatena.ne.jp)交差法と平行法を繰り返すと良いらしい
エンジニアを10年以上やって視力2.0を保つ秘訣 (zenn.dev)報道の日2024 TBSテレビ報道70年〜8つの禁断ニュース[字] | TBSテレビ仁義なき派閥争い田中角栄と三木武夫が歩んだ道
和歌山毒物カレー事件“史上最大”過熱報道で消された目撃証言
唯一の被爆国になぜ?原発導入に日米の思惑
大量破壊兵器のウソCIAの情報捏造検証
トランプ仕掛けた?議会襲撃事件の真相は?
ロシアと北朝鮮が軍事同盟アジアに新たな火種…
メディアに政権の圧力 日本初のキャスター降板
万博成功のカギは? 54年前の予算管理
あさま山荘事件 初公開!突入の記録
独裁政権崩壊へ暗殺を暴いたテレビ報道
ハイジャック16時間報じられなかった突入の瞬間
戦後初の大手銀行破たん元頭取明かす裏舞台
中国外交の分岐点 漁船衝突の裏で…
→偏向報道していますよというTV番組
Posted by funa : 10:32 PM
| Column
| Comment (0)
| Trackback (0)
June 21, 2024
BT
あそびはここで終わりにしようぜ~
Big Table
でっかいテーブル、読み書き低レイテンシー、RDBは負荷高いときにレプ数位でスケールが難しいがBTはするので正規化せずに単一テーブルにしておく感じ
row keyが主役
データを追加するのに3パターンある(行追加、列追加、セル追加)
行に複数カラムファミリーにカラムが幾つか入れられるのでKVSだが結局Where句みたいに使う?
行キー「企業ID#日付」,COLUMN FAMILY「STOCK PRICE」,COLUMN「HI PRICE」「LO PRICE」に対してJSONデータを入れておく等
時間はバージョン管理として持っている
複雑な条件は無理でデータを事前整理して入れておき、JSONカラムを使ったりで一行にまとめスキャンを一発で済ます等で高スループットのみ
Google検索のようにキーワードを入れると、検索結果が数多く一瞬で返る等
複雑な条件はDataprocを使うらしい
Big table構成
インスタンスの中に一つ以上のクラスタ(ゾーン別に設定しレプリケーション)> 各クラスタには1つ以上の同数のノード
クラスタに table > 複数Column family > 複数Column > セル
bigtable_app_profilesで転送クラスタ先の設定する(単一行トランザクション設定を含む)
-マルチクラスタ(自動フェイルオーバ、単一行transaction不可でレプリケーションによる不整合あり)
-シングルクラスタ(手動フェイルオーバ、一行transaction)
デフォルトをマルチにして、通常のクラスタ転送をシングル、問題があるときだけアプリで判定しマルチに行く
スキーマ:
テーブル
行キー(row key)
カラムファミリー(カページコレクションポリシーを含む)
カラム
更新したデータはタイムスタンプによりセル内で保存される
解消するにはガベージコレクション
期限切れ値、バージョン数で設定する
仕様:
KVS、行指向の行単位でスキャン
各テーブルのインデックス (行キー)は1つのみで一意である必要がある
行は、行キーの辞書順に並べ替えられます。
列は、列ファミリー別にグループ化され、列ファミリー内で辞書順に並べ替えられます
列ファミリーは特定の順序では保存されません
集計列ファミリーには集計セルが含まれます
行レベルでアトミック (複数行だと知らんという意)
アトミック性:トランザクション整合性がある(一部の操作だけ実行した状態とならずに)
特定の行にread/writeが集中するより分散が良い
Bigtable のテーブルはスバース、空白行での消費はない
gcloud components update
gcloud components install cbt
(-/cbtrcに以下記載すれば-projectと-instance はデフォルト値で省略できる)
cd ~
echo project unco > ~/.cbtrc
echo instance = chinco >> ~/.cbtrc
cbt -project unco listinstances
cbt -instance chinco listclusters
cbt -project unco -instance chinco ls | grep kuso-t
テーブル名取得
cht -project unco -instance chinco ls kuso-table
カラムファミリやポリシー等取得
cbt -project unco -instance chinco deletefamily kuso-table shikko-family
cbt -project unco -instance chinco deletetable kuso-table
テーブルを消せばカラムファミリも削除になる
Posted by funa : 11:00 PM
| Web
| Comment (0)
| Trackback (0)
June 19, 2024
スト6
///ストートファイター6
隠しシステムを覚えないといけないが膨大にある感じ、練習をして数Fの誤差で手癖を付けないと、、、→いかに反射神経で早く返せるかゲー、アスリートっぽいな、考えると駄目で目で直接に手が動く感じで→低遅延ゲームモードのあるTV欲しい?
- リフレッシュレート:144Hz以上
- 応答速度:1ms以下
モダンタイプという簡易操作法がある:クラシックタイプよりも出せる技が少ない、必殺技が強SAに限定され中SA・弱SAが出せない、ダメージが80%に減少してしまうといったデメリット→純正コントローラの時はモダン?、ホリファイティングコマンダーOCTA買ってクラシックだな
【モダン】
通常攻撃は弱□・中×・強〇
投げ □+×(あるいはL2)
ダウン時にボタン2つで後方受け身
必殺技は必殺技ボタン△
スーパーアーツは強〇+必殺技ボタン△(オーバードライブ:EX技)
アシストボタンR2を押しながら弱/中/強の連打でコンボ技のアシストコンボ
ドライブインパクト L1(相手の攻撃を受けつつもカウンター:セビアタ)
ドライブリハーサル ガード(あるいはR1) > L1+→(防御中の硬直をキャンセルして反撃)
ドライブパリィ R1(防御しドライブゲージを回復:ブロッキング)
パリティドライブラッシュ(ドライブパリティの構えからキャンセルしてダッシュ)
R1>→→ 1ゲージ消費
→>→+R1 の方がやり易い
キャンセルドライブラッシュ (any+→:同時押し)(R1+→:同時押し)(技当ててダッシュ:ガードキャンセル)
攻撃のままR1オシッパにして前前
攻撃キャンセルなので3ゲージ消費
※ドライブラッシュの利点
ガード時とヒット時の相手の仰け反りフレームが4F増加し有利フレームが伸びて、通常時は確定反撃を取られてしまう技が安全に使えるようになったり、通常時は繋がらない技が繋がるようになる、小パンから投げができたり。+4Fということ。
※ドライブゲージ(前に攻めていると良いが、後ろ向きで防御中心だと減るシステムと言える)
消費:相手の攻撃を被弾(ガードでも)
回復:前歩き、時間(ただジャンプ中は回復が遅い)、相手に攻撃を当てる(ガードでも)、ドライブパリティで受ける
【クラシック】
投げ 弱P+弱K
ドライブインパクト 強P+強K
ドライブパリィ 中P+中K
パリティドライブラッシュ 中P+中K+→→、→>→+中P+中K
起き上がりや硬直開けは前者、中2つ押しながら横を連打しとく
通常は後者がいい、PKが遅くなってパリティが出やすいが、詳しくは:
N>→>中PK押しっぱなし>→ が良いと思う、↙防御から→が↘になりがち
キャンセルドライブラッシュ キャンセル可能技>(N or →)+中P+中K
↙中Kキャンセル>N>中P+中Kがいい(人差し指の第一関節で中K>離して>腹で中P)
スト6対戦のセオリー - ストリートファイター6初心者wiki | スト6初心者wiki - atwiki(アットウィキ)
【ストリートファイター6】マスターになるための”必須テクニック” 10選 (youtube.com)
有利フレームがあれば 打撃か投げ の2択ができる
1/60秒=1フレーム=0.0166s、6Fが0.1s
反射は0.2秒(12F)、限界は0.1秒(6F)くらい、インパクト返し0.43秒(26F)でも辛いが
遅らせグラップ
打撃防御と投げ抜けの両方の防御ができる ←>弱P+弱K
起き上がりにガードをしながら、少し待ってから投げを入力
シミ―
有利フレームで投げ間合いから後ろ歩き、遅らせグラップの投げ空振りを誘う
投げ空振りだとパニッシュカウンターとなり高火力コンボに行ける
有利フレームの選択肢
攻撃側:投げか打撃かシミ―、起き攻めは投げが強いが遅らせグラップが来る>その場合垂直ジャンプ
防御側:遅らせグラップか防御かOD無敵技、他はパリティ/バクステ/バックジャンプ
画面端
攻撃側:ドライブインパクト強い、コンボ繋がる、投げ2回
防御側:バクステ反撃、ジャストパリィ後ろ投げ
ファジー
防御しながら相手の攻撃のタイミングで攻撃ボタン、小P入れとく?
発生の早い攻撃には防御、遅い技には割り込み攻撃ができる
安全飛び
ダウンした相手にガード入力をしながらジャンプ攻撃
発生5F以上の対空無敵技に着地後にガードが間に合う
対空しない相手には着地後に下段技からつなげる、あるいは着地後に投げ
仕込み
通常技+必殺技を仕込んで入力しておくと、当たった時だけ必殺技が繋がる
必殺技は早めに入力、遅いと普通に必殺技がでてしまう
ラッシュ仕込み
中か強>→パリィ/Nパリィの入力しておくと、当たった時だけキャンセルラッシュになる、中距離で仕込んでおく
逆に弱>→パリィ/Nパリィなら当たらずともキャンセルラッシュになる
インパクト返し
26F=0.43s内。色変わりを見てドライブインパクトで返す、他には投げる/パリィ/無敵技/3発当てる/アーマブレイク属性
強を振り回すとDI返せない、DI返せる技振りをしておく
キャンセルでインパクト返しがおススメ、小中のキャンセル可能技を確認しておく
連続ガード
有利Fが続き相手が黄色マスで続くヤツ
ドライブリバーサルだけやり返せる
ヒット確認
キャラを見るより体力ゲージが減るかで確認できる
キャンセルラッシュでヒットしなければ弱で防御に回る等の
安全弾
弱波動拳+対空は距離があれば安全
防御側はジャストパリィで有利F伸びる+ジャンプ攻撃で対応できる
ドライブリバーサル複合入力
↗中P+強P+強Kでガード時はドライブリバーサル、相手空振りならOD技??
パリィでSA入力
ゲージがあればSAだが、なければパリィ??
省略入力
↘↓↘Pでも昇竜拳が出る、しゃがみながら昇竜なので対空有利
バーンアウト
ゲージが空、パリティできない、ガード硬直+4Fで反撃ムズイ、必殺技で体力削られる、壁やられでスタン
回復:20s位、ガード/前歩きで早まる、ジャンプで遅くなる
アピール
全6PKボタン(+N、前、後、キャラにより下)??
OPTIONボタンメニュー➡︎OPTION➡︎CONTROL➡︎設定変更>LS/RS/タッチバッドが割り当て
トレーニング
赤は通常技キャンセル可能、青は必殺技をキャンセルしSAに行ける
R3:キャラを変えて準備>レコードの記録開始>レコード記録停止
L3:再生開始
入力
現技が出ているときに次の技ボタンを押す、次の次(の技のボタン)は入れられない(レバー入力はできる)
Ken
ケン コマンドリスト|STREET FIGHTER 6(ストリートファイター6)|CAPCOM
ストリートファイター6 今さら聞けないケンの実用性の高いコンボ(中~上級編)|SUGAKNEE/すがにぃ (note.com)
【スト6】勝てるようになる『ケンの使い方』を解説!初心者におすすめの強い技や立ち回り、コンボ、起き攻めを紹介します!【STREET FIGHTER 6】【ストリートファイター6】 (youtube.com)
【5分下さい】ケンで“実戦向け”コンボを9個に絞って紹介します【スト6】 (youtube.com)
【スト6】ケン 最強コンボ集【プロ解説付き】 (youtube.com)
スト6 ケン とりあえずこれを覚えれば戦えるコンボ - YouTube
Octaポジション:基本は人差し指で弱、中指で中、薬指で強。
→繋がり必要なら:人差し指で中K→中指で大P、人差し指で中P→中指で大Pのタゲコンなど、人差し指を中にズラス
人差し指範囲:弱ボタン2つの投げ
中指範囲:中ボタン2つのパリティ
薬指範囲:強
→ドライブインパクトはLボタンにアサイン
パンパンいわせて強めで叩く(キッチリ2つ押せる、フレーム間隔の手癖化)
顎撥二連 中P>強P
SA(レバー2回)、SA3は体力が25%以下ならクリティカルアーツ(CA)になる
SA1 龍尾烈脚 ↖↖K
SA2 疾風迅雷脚 ↗↗K
SA3 神龍烈破 ZZP
龍尾脚 ZK
迅雷脚 ↓↘→K
風鎌蹴り 中迅雷>派生弱K あばれ潰し
轟雷落とし 中迅雷>派生中K 中段
奮迅脚 KK
奮迅昇竜 KK>派生ZP
奮迅竜巻 KK>派生↖K
奮迅竜尾 KK>派生ZK(入れ替え)
OD(ボタン2つ)
OD波動拳 ↗PP
OD竜巻旋風脚 ↖KK
OD昇龍拳 ZPP
OD龍尾脚 ZKK
OD迅雷脚 ↗KK >派生K >→K
///コンボ
(中P>強P)顎撥2連>(間KK>↖K)奮迅竜巻(遅めでギリギリ間に合う感じで、↖が不完全>ゆっくり目で、最後←押しっぱが良さそう)
顎撥2連>(間KK>ZK)奮迅竜尾脚>昇竜(間を少な目がいい)
強P>OD波動>SA 4400
///反射
何か技がヒット or ラッシュ>顎撥二連>奮迅竜巻 or 大昇竜
強P or ↓中K>中P+中K>中P>強P>KK>↙K
↓中K or 強P>キャンセルラッシュ
↓中K>弱竜巻>中昇竜 2500:竜巻早く入力
パニッシュカウンター強K>ラッシュ>強P>奮迅竜巻
///基本
波動拳からの対空昇竜、対空は弱昇竜(読みで事前にレバーは入れて置き、来たらPで)
防御から昇竜の場合はレバーの手の移動距離が長いので反射神経+大げさにレバーを動かす
弱波動をラッシュで追いかけ攻撃
↓中K>迅雷>派生弱Kか中K(ゲージ回復)
↓中K>迅雷脚>派生>波動 で距離をとる
後ろ前歩きでチョロチョロ間合い取り>読み合い(置き/差し/差し返し):長距離強K/強P/中↓K/弱
リーチが長い技は遅い強、早い技は弱
しゃがみ防御から迅雷脚は入れやすいし、長距離+派生で使える
しゃがみ中Kキャンセル>ラッシュか波動か弱竜巻+中昇竜
相手の硬直にカウンターコンボ
中距離で竜尾脚 or 生ラッシュ、他の狙いはカウンターでジャスパ/ドライブインパクト
起き攻め
ラッシュ投げ、ラッシュ>顎撥二連>奮迅竜巻/大昇竜
↓小K>↓中K>迅雷脚>派生
(屈)小Px2>大昇竜 屈小Pヒット確認練習
端
屈大P>迅雷>強派生>弱昇竜
顎撥二連>奮迅竜尾脚>昇竜
Ryu
中下:足払い と 強前:まわしげり のリーチ長いやつ
中前:中段鎖骨割り2発(立ちガードが必要なので良き技となる)
強後:かかとおとし2発
スト6リュウ体験版モダンコンボとか雑感まとめ|アズサキチャンネル【東和正/戸崎時貞】 (note.com)
【スト6体験版】モダン リュウ コンボまとめ in Demoバージョン【Modern Ryu】 - YouTube
【スト6(OBT)】必要十分!リュウ実用コンボ(モダンTYPE)【RYU basic combo】 - YouTube
【スト6】知らないと損!意外と知らないスト6豆知識集!【テクニック】 - YouTube
【初心者向け】全キャラの強技や強連携の対策教えます!【スト6】 - YouTube
===========
内臓と外付けをSSD化
実はカンタン!PS4のSSD化 | 株式会社アスク (ask-corp.jp)
PS4を外付けSSDで高速化させる方法を解説。内蔵HDD換装より手軽にできる! - 価格.comマガジン (kakakumag.com)
PS4®の内蔵ドライブをSSDに換装して高速化しよう! -エレコム (elecom.co.jp)
Posted by funa : 12:36 AM
| Column
| Comment (0)
| Trackback (0)
June 2, 2024
Cloud SQL
■Cloud SQL Python Connector (Cloud SQL language Connector)
CloudSQL auth proxyのバイナリインストールでないやり方
Cloud SQL Python Connector自体は暗号化しないが、内部IPならサーバレスVPCコネクタで暗号化された通信が使え安全になっている。外部IPアドレスの場合はCloud SQL Auth Proxyで通信を暗号化。
事前必要(pip install>requirements.txt)
Flask==3.0.3
gunicorn==22.0.0
Werkzeug==3.0.3
google-cloud-bigquery==3.25.0
google-cloud-logging==3.11.1
google-cloud-secret-manager==2.20.2
google-api-python-client==2.141.0
google-auth-httplib2==0.2.0
google-auth-oauthlib==1.2.1
websocket-client==1.8.0
google-cloud-resource-manager==1.12.5
Flask-WTF==1.2.1
cloud-sql-python-connector==1.16.0
pymysql==1.0.3
from flask import Flask, jsonify
from google.cloud.sql.connector import Connector
from google.cloud import secretmanager
import pymysql
# 環境変数の定義
PW_NAME = "sql-pw"
PROJECT_NUM = "1234567890"
DB_INSTANCE = "prj:asia-northeast1:db_instance"
DB_USER = "db-user"
DB_NAME = "db001"
# Secret Manager からパスワードを取得する関数
def get_pw(pw_name, project_num):
client = secretmanager.SecretManagerServiceClient()
resource_name = f"projects/{project_num}/secrets/{pw_name}/versions/latest"
res = client.access_secret_version(name=resource_name)
credentials = res.payload.data.decode("utf-8")
return credentials
# Cloud SQL接続
def sql_getconn(connector):
pw = get_pw(PW_NAME, PROJECT_NUM)
conn = connector.connect(
DB_INSTANCE,
"pymysql",
user=DB_USER,
password=pw,
db=DB_NAME,
ip_type="private",
)
return conn
app = Flask(__name__)
@app.route('/test', methods=['GET'])
def get_table_data():
try:
connector = Connector()
conn = sql_getconn(connector)
cursor = conn.cursor()
# SQLを実行して結果を取得
cursor.execute("SELECT no, name, targetDate FROM test")
rows = cursor.fetchall()
# 結果をJSON形式に変換
result = [
{
"no": row[0],
"name": row[1],
"targetDate": row[2].strftime("%Y-%m-%d %H:%M:%S") if row[2] else None
}
for row in rows
]
cursor.close()
conn.close()
return jsonify(result), 200
except Exception as e:
return jsonify({"error": str(e)}), 500
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080)
=============
# 追加オプションを使った接続も可
connector = Connector(
ip_type="public", # "private" または "psc" も使用可能
enable_iam_auth=False,
timeout=30,
credentials=None, # 必要ならGoogle認証情報を渡す
refresh_strategy="lazy", # "lazy" または "background"
)
#トランザクション
try:
conn = sql_getconn(connector)
conn.autocommit = False # トランザクション開始、あるいは conn.begin()
cursor = conn.cursor()
# 挿入するデータを準備
new_data = [
{"no": 4, "name": "新しい名前4", "targetDate": "2024-05-01"},
{"no": 5, "name": "新しい名前5", "targetDate": "2024-05-02"},
]
# INSERT文を構築して実行
for data in new_data:
sql = "INSERT INTO test (no, name, targetDate) VALUES (%s, %s, %s)"
values = (data["no"], data["name"], data["targetDate"])
cursor.execute(sql, values)
conn.commit() # トランザクションをコミット
print("Data inserted successfully.")
except Exception as e:
conn.rollback() # エラーが発生した場合はロールバック
print(f"Transaction rolled back due to an error: {e}")
finally:
cursor.close()
conn.close()
#カーソル
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
params: dict形式で取得#[{'no': 1, 'name': 'Alice',...}, ...]
cursor = conn.cursor(cursor=pymysql.cursors.SSCursor)
大量のデータを効率的に取得するためにストリーミングで結果を処理
cursor.execute(query, params=None)
cursor.execute("SELECT * FROM test WHERE no = %s", (1,))
params: プレースホルダーに対応する値のタブルまたはリスト
cursor.executemany(query, param list)
cursor.executemany("INSERT INTO test (no, name) VALUES (%s, %s)", [(1, 'Alice'), (2, 'Bob')])
param list:繰り返し実行するパラメータのリストまたはタブルのリスト
cursor.fetchone()
row = cursor.fetchone()
#結果があれば (1, 'Alice', "2025-01-01") のような形式で1行のみ取得
cursor.rowcount
print(cursor.rowcount) #影響を受けた行数を返す
■接続検証用コンテナをビルド (内部IPを使うrun用)
gcloud builds submit --tag asia-northeast1-docker.pkg.dev/prj/artifact_reg_name/app_name
■IAM?
Cloud SQL設定にCloud SQL 管理者 (roles/cloudsql.admin)、Cloud SQL インスタンス ユーザー (roles/cloudsql.instanceUser)等のIAMが要る?
IAMユーザならいる、ローカルUserなら不要と思われる、ローカルでもCloud SQL Client (roles/cloudsql.client)等は要る
■Cloud SQL MySQL設定
【開発環境】db_instance01
Enterprise / Sandbox / AsiaNorthEast1 (Tokyo) / Single zone
MySQL ver 8.4
Shared core/1cpu 0.6GB/HDD/10GB(auto increase)
PrivateIP/設定にnwが必要(下記)/Enable private path
Auto daily backup 7days (1-5AM) / Enable point-in-time recovery
Week1 sun 0-1am/Enable query insights
root PW: 69696969
【本番環境】
Enterprise plus? キャッシュ使う?
※CloudSQLはTFファイルに記載がなくてもTFステートファイルにPWを含めてしまうためTF化しない
- NW: projects/prj/global/networks/sql-vpc-nw
- Connection name: prj:asia-northeast1 db_instance01
ユーザの作成 sql-user/82828282
PWをコードに入れない、シクレMgrに保存
■MySQL
utf8mb4_ja_0900_as_ci_ksを使う?
_ai... アクセントを区別しない (Accent Insensitive)
_as... アクセントを区別する (Accent Sensitive)
_ci... 大文字・小文字を区別しない (Case Insensitive)
_cs... 大文字・小文字を区別する (Case Sensitive)
_ks... カナを区別する (Kana Sensitive)
_bin... バイナリ
utf8mb4_unicode_ciでは"ア”と“あ”は同じものとして扱われる
utf8mb4_ja_0900_as_ci_ks では"ア"≠”あ”となりカタカナとひらがなを明確に区別できる
utf8mb4_ja_0900_as_ci_ks ならふりがなを使った並び替えで有効
日本語のデータがメインで検索やソートでひらがな・カタカナ・濁点の区別が必要なら utf8mb4_ja_0900_as_ci_ks が適
データベースとテーブルの作成
CREATE DATABASE db;
USE db;
CREATE TABLE test (
no INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(8) NOT NULL,
targetDate TIMESTAMP NOT NULL,
PRIMARY KEY (no),
INDEX index_name (name),
INDEX index_targetDate (targetDate)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_ja_0900_as_ci_ks;
ENUM型は選択肢で早いがALTERが面倒なのでvarcharaにする
inquiry_type ENUM('bq', 'pii') NOT NULL
↓
inquiry_type VARCHAR(255) NOT NULL,
VARCHAR(255) (よく使われる最大サイズ)
VARCHAR(1024) (長めの文字列)
VARCHAR(4096) (長文向け)
長いテキストを扱うならTEXT型
InnoDB の1行の最大サイズは約8KB (8126/バイト)
長さは?メールは255で良い
サンプルデータ
INSERT INTO `table` (`name`, `date`) VALUES ('aaa', '2002-02-23');
ORMapperは面倒なのでSQLを使う
ORM Quick Start — SQLAlchemy 2.0 Documentation【SQLAlchemy】Generic Typesと各種DBの型 対応表SQLAlchemyでのテーブル定義 #Python - Qiita■データベースフラグ
confが直接変更できなためフラグとしてパラメータを渡せる
Cloud SQL studio (コンソールでMySQLが使える)
MySQLクライアントを使いたいならAuth proxyが必要
Cloud SQLが内部IPだとサーバレスVPCコネクタ、or 外部IPならSQL + auth proxy
内部IPで良いのでVPCを作る、CloudSQLを内部IPで作る
サーバレスVPCアクセスコネクタを作る
vpc: sql-vpc-nw, subnet: sql-vpc-subnet 192.168.77.0/24
Gateway 192.168.77.1, Private Google Access On
sql-vpc-nw-ip-range 192.168.78.0/24 on cloudSQL
run-serverless-vpc-ac 192.168.79.0/28 on Run
ファイアウォールルールでポート (デフォルトで3306など) を開放
Cloud Run のNW設定で、サーバーレス VPCコネクタを選択、ルートオプションとしてすべてのトラフィックを VPC コネクタ経由で送信を選択
CloudSQLを30分程度掛けて起動、接続>接続テスト
VPC(例: 10.0.0.0/16)
サブネット(Cloud SQL 用): 10.10.0.0/24(例: us-central1、VPC内)
サブネット(VPCコネクタ用): 10.8.0.0/28(RunからVPCへ通信用、VPC外)
VPC コネクタのサブネットは 10.8.0.0/28 のような小さな範囲を使用、VPC外だがrun自体がVPC外だから?
VPC コネクタはリージョン単位なので、Cloud Run と Cloud SQL を同じリージョンに配置するのが望ましい
Google Cloudの内部NW設計によりVPC内の異なるサブネット間でも通信可能
VPC内なら異なるリージョンのサブネットでもOK(VPC自体には範囲を設定なしでサブネットでIPが被らなければOKかと
追加の設定なしで、例えば us-central1 の VM から asia-northeast1 の Cloud SQLに直接アクセス可
外部IPの場合:
アプリがrunならサイドカーコンテナとしてAuth Proxyを追加できる
サイドカーは同Pod内なのでループバックアドレス127.0.0.1あるいはlocalhost:5432 (Auth Proxy起動時に指定したポート) に通信しCloudSQLに接続する
GCEにDLしてAuth proxyインストールでもいい
アプリのコネクタはAuth Proxy動いているGCEのIP:ポート番号を指定に通信しCloudSQLに接続する
FWでポートも開けること
■run サービスアカウント
run-sql@prj.iam.gserviceaccount.com に必要な権限
Cloud SQL Client (roles/cloudsql.client)
Run Invoker (roles/run.invoker)
Compute Network User (roles/compute.networkUser) -VPCコネクタを使用する
runを建てるが、InternalIPのため同プロジェクト同VPCのGCE を作成し移動してCURLでテスト
curl -H "Authorization: Bearer $(gcloud auth print-identity-token)" "https://run-sql-test-1212124.asia-northeast1.run.app/test"
■MySQLでUUIDを使うか、連番を使うか? > ULIDを使う
UUIDは連番に対し
セキュリティ上より安全、サーバが異なってもユニーク
パフォーマンスが悪い (UUIDをプライマリキーにすると速度が落ちる場合がある)
連番とUUIDの両方を振り出しておく? > ULIDを使うことにする
Posted by funa : 01:06 PM
| Web
| Comment (0)
| Trackback (0)
June 1, 2024
GCP hands-off 3
■VPC(例: 10.0.0.0/16)
サブネット(Cloud SQL 用): 10.10.0.0/24(例: us-central1、VPC内)
サブネット(VPCコネクタ用): 10.8.0.0/28(RunからVPCへ通信用、VPC外)
VPC コネクタのサブネットは 10.8.0.0/28 のような小さな範囲を使用、VPC外だがrun自体がVPC外だから?
VPC コネクタはリージョン単位なので、Cloud Run と Cloud SQL を同じリージョンに配置するのが望ましい
Google Cloudの内部NW設計によりVPC内の異なるサブネット間でも通信可能
VPC内なら異なるリージョンのサブネットでもOK(VPC自体には範囲を設定なしでサブネットでIPが被らなければOKかと
追加の設定なしで、例えば us-central1 の VM から asia-northeast1 の Cloud SQLに直接アクセス可
■対象アセットに対する付与可能なロールの一覧表示
Full Resource Name(フルでのアセット名を探せる)
import google.auth
import googleapiclient.discovery
def view_grantable_roles(full_resource_name: str) -> None:
credentials.google.auth.default(
scopes=["https://www.googleapis.com/auth/cloud-platform"]
)
service = googleapiclient.discovery.build('iam', 'v1', credentials credentials)
roles = (
service roles()
queryGrantableRoles (body=["fullResourceName": full_resource_name}).execute()
)
for role in roles["roles"]
if "title" in role:
print("Title: role["title"])
print("Name: role["name"])
if "description" in role:
print("Description:" + role["description"])
print("")
project_id = "prj"
#resource = f"//bigquery.googleapis.com/projects/prj/datasets/ds"
#resource + f"//bigquery googleapis.com/projects/prj/datasets/ds/tables/tbl"
resource = f"//cloudresourcemanager.googleapis.com/projects/{project_id}"
view_grantable_roles(resource)
■ロールの一覧表示
https://cloud.google.com/iam/docs/roles-overview?hl=ja#role-types
1)事前定義ロールの場合は roles.get() を使用します。
2)プロジェクトレベルのカスタムロールの場合は、projects.roles.get() を使用します。
3)組織レベルのカスタムロールの場合は、organizations.roles.get() を使用します。
これら3種類で全てを網羅すると思われます
projectIDがsys-のものはGAS、lifecycleStateがACTIVE以外のものも含まれるので注意
■bqへの書き込み
export GOOGLE_APPLICATION_CREDENTIALS="path/to/your-service-account-key.json"
pip install google-cloud-bigquery
from google.cloud import bigquery
client = bigquery Client()
#書き込み先のテーブル情報
table_ref = f"{project_id}.{dataset_id}.{table_id}"
#サンプルデータの生成
def generate_sample_data(num_rows)
data = [
{
"organization": f"org_(num_rows)",
"permission". "view",
}
for _ in range(num_rows)
]
return data
data_to_insert = generate_sample_data(5000)
errors = client.insert_rows_json(table_ref, data_to_insert)
if errors:
print("Errors occurred: {errors}")
else:
print("Data successfully written to BigQuery!")
■データカタログ
データアセットを検索する | Data Catalog Documentation | Google CloudClass SearchCatalogRequest (3.23.0) | Python client library | Google Cloudサンプルで仕様書のAPIを使っているがqueryが空白刻みで入れる等の使い方が分かる
■BQスキーマ+ポリシータグ取得
from google.cloud import bigquery
def get_policy_tags_from_bq_table(project_id, dataset_id, table_id):
print("################ bigquery.Client.get_table().schema start ################")
print(f"Target table: {project_id}.{dataset_id}.{table_id}")
bq_client = bigquery.Client()
table = bq_client.get_table(f"{project_id}.{dataset_id}.{table_id}")
schema = table.schema
policy_tags = []
for field in schema:
print(f"Column: {field.name}")
if field.policy_tags:
tags = [tag for tag in field.policy_tags.names]
policy_tags.extend(tags)
print(f"Policy Tags: {tags}")
else:
print("> No Policy Tags assigned.")
return policy_tags
PROJECT_ID = "prj"
DATASET_ID = "ds"
TABLE_ID = "test001"
policy_tags = get_policy_tags_from_bq_table(PROJECT_ID, DATASET_ID, TABLE_ID)
print("Collected Policy Tags:", policy_tags)
■ポリシータグ設定
from google.cloud import datacatalog_v1
from google.cloud import bigquery
PROJECT_ID = "prj"
DATASET_ID = "ds"
TABLE_ID = "tbl01"
COLUMN_NAME = "aaa"
POLICY_TAG_PROJECT = "prj"
POLICY_TAG_NAME = "projects/prj/locations/us/taxonomies/83893110/policyTags/11089383"
def list_taxonomy_and_policy_tag():
print("############# Start #############")
list_policy_tags = []
client = datacatalog_v1.PolicyTagManagerClient()
request = datacatalog_v1.ListTaxonomiesRequest(
parent=f"projects/{POLICY_TAG_PROJECT}/locations/us"
)
try:
page_result = client.list_taxonomies(request=request)
except google.api_core.exceptions.PermissionDenied as e:
print(f"Skipping project {POLICY_TAG_PROJECT} due to PermissionDenied error: {e}")
return []
except Exception as e:
print(f"An error occurred for project {POLICY_TAG_PROJECT}: {e}")
return []
for taxonomy in page_result:
print(f"############ Taxonomy display_name: {taxonomy.display_name} #############")
print(f"############ Taxonomy name: {taxonomy.name} #############")
request_tag = datacatalog_v1.ListPolicyTagsRequest(parent=taxonomy.name)
try:
page_result_tag = client.list_policy_tags(request=request_tag)
except Exception as e:
print(f"Error on {request_tag}: {e}")
break
for policy_tag in page_result_tag:
print("Policy tag:")
print(policy_tag)
list_policy_tags.append({
"project_id": POLICY_TAG_PROJECT,
"taxonomy_display_name": taxonomy.display_name,
"taxonomy_name": taxonomy.name,
"policy_tag_name": policy_tag.name,
"policy_tag_display_name": policy_tag.display_name,
})
return list_policy_tags
def update_table_schema_with_policy_tag(list_policy_tags):
for policy_tag in list_policy_tags:
if policy_tag['policy_tag_name'] == POLICY_TAG_NAME:
print(
f"Target policy tag:\n"
f" Project ID: {policy_tag['project_id']}\n"
f" Taxonomy Display Name: {policy_tag['taxonomy_display_name']}\n"
f" Taxonomy Name: {policy_tag['taxonomy_name']}\n"
f" Policy Tag Name: {policy_tag['policy_tag_name']}\n"
f" Policy Tag Display Name: {policy_tag['policy_tag_display_name']}"
)
client = bigquery.Client()
table_ref = f"{PROJECT_ID}.{DATASET_ID}.{TABLE_ID}"
table = client.get_table(table_ref)
new_schema = []
for field in table.schema:
if field.name == COLUMN_NAME:
new_schema.append(
bigquery.SchemaField(
name=field.name,
field_type=field.field_type, # Keep original field type
mode=field.mode, # Keep original mode
description=field.description,
policy_tags=bigquery.PolicyTagList([POLICY_TAG_NAME]),
)
)
else:
new_schema.append(field)
table.schema = new_schema
updated_table = client.update_table(table, ["schema"])
print(
f"Updated table {updated_table.project}.{updated_table.dataset_id}.{updated_table.table_id} schema\n"
f"with policy_tag {POLICY_TAG_NAME} on the column {COLUMN_NAME} successfully."
)
if __name__ == "__main__":
list_policy_tags = list_taxonomy_and_policy_tag()
update_table_schema_with_policy_tag(list_policy_tags)
■KSA問題
ブログ内で情報が分散、まとめたい
ワークロード毎にKSA1つ
ksaのtokenはk8s api用でgcp apiに使えない、exprireしない問題がある> Workload identity で解決する
Workload Identity は KSAとGSAの紐づけで、Workload Identity Federationとは違う
workloads がk8sの用語でリソースの総称で、そのidentityであり権限管理、でFederationは更に外部連携
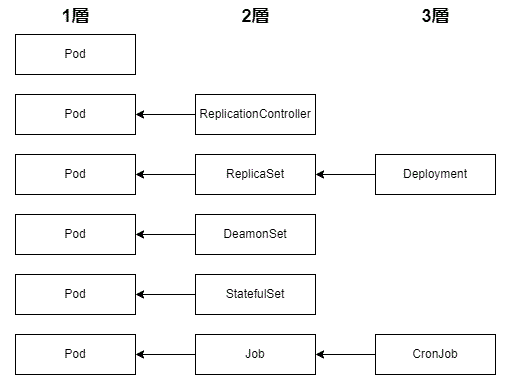
ワークロードは、pod, deplyment, StatefulSet, DaemonSet, job, CronJob, ReplicationController, ReplicaSet
Workload Identity がGKE クラスタで有効化されると、gke-metadata-server という DaemonSet がデプロイ
gke-metadata-server は Workload Identity を利用する上で必要な手続きを実行
SAの紐づけ
/// 現行
Workload identityを有効にして(autopilot でデフォルト有効)
GCP側でKSAとGSAをIAM policy binding
k8s側でKSAとGSAをkubectl annotate
podでKSAを設定
↓
/// 新型のKSA直接bind
workload identity federation ならGSAがなくなりKSAを直接bindできる
Workload identityを有効にして(autopilot でデフォルト有効)
GCP側でKSAにIAM policy binding
※混在するので現行のままが良いようです
まずWIF用のSAを作成する>SAに権限を付与する>
1)Workload identity provider+SAの情報をgithub actionに埋めて使う
GitHub Actions から GCP リソースにアクセスする用途
2)Workload identity poolから構成情報をDLしAWSアプリに埋めて使う
AWSからGCP リソースにアクセスする用途
gcloud auth login-cred-file=構成情報ファイルパス
3)Workload identity poolから構成情報をEKSのOIDC ID token のパスを指定しDL
EKS から GCP リソースにアクセスする用途
- EKSのマニフェストのサービスアカウントのアノテーションにIAMロールを記載
- EKSのサービスアカウントを使用したい Podのアノテーションに追加
- マウント先のパスを環境変数 GOOGLE APPLICATION_CREDENTIALS に設定
- Pod内でSDK またはコマンドにてGCP リソースヘアクセス可能か確認
Posted by funa : 03:24 PM
| Web
| Comment (0)
| Trackback (0)
May 9, 2024
Pubsub
■pubsub
アプリで簡単にPubsubにパブリッシュや、サブスクもできるので、アプリ間の連携にPubsubが使える
• 非同期処理(画像処理とか重めのもの
• IDの種類 (message id, subscription id, topic id, ack id, project idあたりがアプリでは使われるっぽい
※ack idはpull時のみでPushのときはhttpステータスコードが200でackとなる
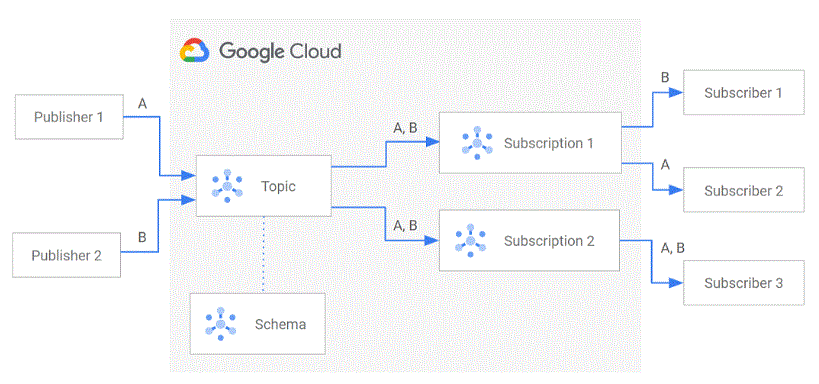
トピック(メッセージのパブリッシュ先)
• スキーマ/外部アクセス許可/リテンション/GCS/バックアップの設定がある (Push/Pullの設定はない)
• パブリッシュ側のベストプラクティス (JWT)
サブスクライバのPushとPull (PushはEndpointが必要、デフォルトはpull)
• at-least-once (少なくとも1回) 配信を提供します
• 同じ順序指定キーを持ち、同じリージョンに存在している場合は、メッセージの順序指定を有効にできます
• サブスクライバーが31日間未使用、またはサブスクリプションが未更新の場合、サブスクリプションは期限切れ
pushはhttpsが必要?
• push エンドポイントのサーバーには、認証局が署名した有効な SSL証明書が必要でhttps
• Cloud run でEvent Arcを設定するとサブスクが自動作成されrunのデフォルトhttpsのURLが使われるが、これはPullよりPushで安定した
• CronバッチならPullで安定するのでは?大量リクエストはPull向きとある(Pullは失敗処理込みの話かも知れん)
トピックのリテンション:デフォルトなし、最小値:10分、最大値:31日
サブスクのリテンション:デフォルト値:7日、最小值:10分、最大値:7日
pubsub ack期限(Ack Deadline)
•デフォルト60秒> 設定10分>ack延長で最大1時間まで伸ばせると思われる
•exactly onceを設定しなければ期限の延長は保証されない
•ack期限を過ぎる、あるいはNackを返す場合、メッセージは再配送される
•ack応答期限の延長は99パーセンタイル(上位1%の値よりも小さい値のうち最大の値)で
modifyAckDeadlineを返し、延長してもMaxExtension (ack期限を延長 する最大値) 60minまで?
modifyAckDeadlineリクエストを定期的に発行すればよいらしい
メッセージの再試行を強制するには
•nack リクエストを送信
•高レベルのクライアント ライブラリを使用していない場合は、ackDeadlineSeconds を0に設定して modifyAckDeadline リクエストを送信する
•pullなら設定できる。他には、Cloud Dataflowを組み合わせる(プログラムコードでDataflowを使う感じかり、あるいはmessageについているunique idを利用して、KVS を用いたステート管理をして自前で重複を排除する
•再配信は、メッセージに対してクライアントによる否定確認応答が行われた場合、または確認応答期限が切れる前にクライアントが確認応答期限を延長しな かった場合のいずれかか原因で発生することがある。
※exactly onceはエラーでも再配信でPubsubパニックしないようにしたいために使うものではない?
pubsubはトピックにPublishされたメッセージをDataflowに引き継げる
Dataflow (Apache Beam) を大量のメッセージをバッチ処理する場合に使える
Pub/Sub→Dataflow→処理
•Apache Beamのウィンドウ処理とセッション分析とコネクタのエコシスエムがある
•メッセージ重複の削除ができる
•pubsub>dataflow>BQやGCS: この流れでログ等をストーリミングで入れ込める
BQサブスクリプション (PubSubはBigQuery Storage Write API を使用してデータを BigQueryテーブルに送信、GCSサブスクもある)
サブスクライバーApp側のコードでのフロー制御によりちょっと待てよのトラフィック急増対応
デッドレタートピック (配信試行回数が見れる)やエラーでの再配信
• Pub/Subサブスクリプションにデッドレタートピックを設定しておくと、一定の回数再送信が失敗したメッセージの宛先がデッドレタートピックに変更され貯められる
メッセージのフィルタ、同時実行制御により多いメッセージに対応
Pubsubをローカルでエミュレートする
pubsubのスナップショットやリテンション
トピックにリテンションを設定しスナップショット作成> 過去のサブスクしたメッセは見えなさそう
サブスクにリテンションを設定しスナップショット作成> 過去のAckしたメッセは見えなさそう
スナップショットでどう使うのか?
キューがたまっているときに撮るものと思われる。またシーク時間のポイントを設定する意味がある
スナップショットとシークを使いこなして特定期間の再実行を行う機能
スナップショットで再実行する
シークは指定時間か最後のスナップショット以降のサブスク再実行(実際pushでrunが再実行された)
Pubsubにどんなメッセージが入ってきているか確認する方法
pull形式ならAckしなければpullボタンで拾い見れる (トピックでパブリッシュしてサブスクでPull し見る)
トラブルシュートはログを見るかデッドレタートピックかGCSバックアップを見る?
デッドレターキュー(ドロップしたものの確認と救済?)
サブスクでDLQのONしデッドレタートピックを設定し転送する>GCSにもバックアップできる
DLTでメッセージ(実行済みOR未実行)の再生
データ形式:スキーマを使うか、スキーマなしならdataで取得できる
from google cloud import pubsub_v1
from avro.io import DatumReader, BinaryDecoder
from avro schema import Parse
project_id="your-project-id"
subscription id="your-subscription-id"
subscriber pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path(project_id, subscription_id)
avro_schema = Parse("""
{
"type": "record",
"name": "Avro".
"fields": [
{
"name": "ProductName",
"type": "string",
"default":""
},
{
"name": "SKU",
"type": "int",
"default": 0
}
}
def callback(message):
print(f"Received message: {message}")
reader = DatumReader(avro_schema)
decoder = Binary Decoder (message.data)
avro_record = reader.read(decoder)
message_id=message.message id
message.ack()
print("Message ID: (message_id}")
product_name = avro_record['ProductName']
sku= avro_record['SKU']
print("Product Name: (product_name}")
print("SKU: (sku}")
subscriber.subscribe(subscription_path, callback=callback)
def callback(message):
print("Received message: (message)")
data message data
message_id=message.message_id
message.ack()
print("Date (data)")
print("Message ID: (message_id)")
Pub/SubでStreamingPull APIを使用してメッセージをリアルタイムで処理する - G-gen Tech BlogStreamingPull API を使用するとアプリとの間で永続的な双方向接続が維持され、Pub/Sub でメッセージが利用可能になるとすぐに pullされる。1 つの pull リクエストで 1 つの pull レスポンスが返る通常の 単項 Pull と比較すると、高スループット・低レイテンシ。必要なメッセージを残す処理をしたりも?GCP側の問題であっても通信が切れた場合は別サーバに繋ぎなおすためmodifyAckDeadlineも切れ再配信されるバグがある
+++
メッセージのTTL (Time-To-Live) はメッセージ保持期間(message retention duration) に依存
メッセージが TTLを超えると、自動的に削除され、Subscriberが受信できなくなる
ackDeadlineSeconds (デフォルトは10秒、最大600秒) を超えたACKのメッセージは再配信されますが、TTL期限を超えた場合は消える
#TTLを最大7日間に設定
gcloud pubsub subscriptions update my-subscription message-retention-duration=604800s
DLQ (Dead Letter Queue)
Subscriberが指定回数(最大100回) メッセージのACKを行わなかった場合に、メッセージを隔離する仕組み
DLQもサブスクなので期間やTTL設定方法は同じ
#DLQ topic 作成
gcloud pubsub topics create my-dlq-topic
#5回失敗したらDLQへ
gcloud pubsub subscriptions update my-subscription dead-letter-topic=projects/my-project/topics/my-diq-topic max-delivery-attempts=5
#DLQ subsc作成
gcloud pubsub subscriptions create my-diq-subscription--topic-my-diq-topic
#サブスクの詳細確認
gcloud pubsub subscriptions describe my-diq-subscription
#DLQメッセージの確認、-auto-ackも付けられるが、
gcloud pubsub subscriptions pull my-dlq-subscription -limit=10
[{
"ackld": "Y3g49NfY...=",
"message": {
"data": "SGVsbG8gd29ybGQ=", #Base64 エンコードされたデータ
"messageld": "1234567890",
"publish Time": "2024-02-18T12:34:56.789Z"
}
}]
#base64のでコードが必要
echo "SGVsbG8gd29ybGQ=" | base64-decode
#ack-idによりackを返しDLQメッセージを削除
gcloud pubsub subscriptions acknowledge my-diq-subscription--ack-ids=Y3g49NfFY
モニタリング > アラートポリシーから新しいアラートを作成し
pubsub.subscription.outstanding_messages を監視対象に選択し、閾値を設定するとよい
#DLQ メッセージの再処理をfunctionsに設定 (トピックに入れなおす)
from google.cloud import pubsub_v1
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path("my-project", "my-topic")
def republish_message(message):
future = publisher.publish(topic_path, message.data)
print(f"Republished message ID: {future.result()}")
subscriber = pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path("my-project", "my-dlq-subscription")
def callback(message):
print(f"Received message: {message.data}")
republish_message(message)
message.ack()
subscriber.subscribe(subscription_path, callback=callback)
Posted by funa : 12:00 AM
| Web
| Comment (0)
| Trackback (0)
April 27, 2024
HELM
helmはコマンド一発だが生k8sはマニフェストファイルの数だけkubectl apply(delete)を繰り返す必要がある
helm upgrade chart名 -f 環境毎yamlファイル
文法覚えるより繰り返した方がええんじゃない
helmはテンプレートフォルダ以下がマニフェスのようなもの
ループ処理が記述可、関数が使える、関数を作れる
helmは基本はテキストの整形用と言える(ヘルパー関数やビルトイン関数を使い外部ファイルを取り込んで変形したり、変数yamlを環境yamlで上書きし外部の値を使う等で沢山のGKEアセットをループ的に生成しようとしている)
helm create <チャート名>
templates/ マニフェスト (テンプレート)
env/ 自分で作成するが環境毎に異なる値の入る変数を記述
┣dev.yaml
┣prd.yaml
values.yaml 繰り返す値等 (dev/prd.yamlが優先され上書きされる)
helm upgrade-install <release名> <Helmチャートの圧縮ファイル名>
●●helmテンプレートの文法 (.ファイル名.親.子で表す、.はルートオブジェクト、Valuesはvaluesオブジェクト、$変数:=値、ymlインデントはスペース2つ)
●templates/deployment.yaml
{{ $env := Values.environment }}
{{ $serviceAccountName := Values.serviceAccountName }}
image: {{ .Values.deployment.image }}:{{.Values deployment.imageTag }} //nginx:latest
serviceAccountName: {{ $serviceAccountName }}-{{ $env }} //sample-sa-dev
↑
●values.yaml
deployment:
image: nginx
imageTag: latest
serviceAccountName: sample-sa
●env/dev.yaml
environment: dev
※values.yaml よりdev/prd.yamlが優先され上書きされ.Valueで使う
●●helmテンプレートのループ (range~end)
●templates/es.yaml
spec:
nodeSets:
((- range .Values.es.nodeSets }}
name: {{ .name }}
config:
node.attr.zone: {{ .zone }}
{{- end }}
↑
●values yami
es:
nodeSets:
- name: node-a
zone: asia-northeast1-a
- name, node-b
zone: asia-northeast1-b
●●helmテンプレートのIF (if-end)
●templates/ingress.yaml
((- if .Values.ingress.enabled -))
apiVension: networking k8s.io/v1
kind: Ingress
{(- end }}
●env/prd.yaml
ingress:
enabled: true
●env/dev.yaml
ingress:
enabled: false
●●helmテンプレートの複数値 (toYaml、nindentは関数)
●templates/ingress.yaml
metadata:
annotations:
{{- toYaml .Values.ingress.annotations | nindent 4 }}
●values.yaml
ingress:
annotations:
kubernetes.io/ingress.global-static-ip-name: sample-ip-name
kubernetes.io/ingress.class: "gce-internal"
●●その他
中括弧内側の前後にダッシュ {{--}} をつけることができ、前に付けた場合は前の半角スペースを、 後ろにつけた場合は改行コードを取り除く
hoge:
{{- $piyo := "aaa" -}}
"fuga"
/* */で囲まれた部分はコメント構文
helm create [チャート名]で自動でtemplates ディレクトリに_helpers.tplが作成されるが、 partialsやhelpersと呼ばれる共通のコードブロック (defineアクションで定義されtemplateアクションで呼び出される)や、ヘルパー関数などが定義される。
_アンスコ始まりのファイルは、他のテンプレートファイル内のどこからでも利用できるという共通部品。 これは内部にマニフェストがないものとみなされる。
種類としては、values.yamlが差し替え可能な変数、ローカル変数が定義したTemplateファイル内でのみ使える変数、_helpers.tplはチャート内で自由に使える変数
●templates/_helpers.tpl
{{- define "deployment" -}}
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: {{.name }}
name: {{ .name }}-deployment
spec:
replicas: {{ .replicas }}
selector:
matchLabels:
app: {{ .name }}
template:
metadata:
labels:
app: {{.name}}
spec:
containers:
- image: {{ .image }}
name: {{ .name }}
{{- end -}}
●values.yaml
nginx:
replicas: "1"
name: nginx
image: docker.io/nginx:1.25.1
httpd:
replicas: "3"
name: httpd
image: docker.io/httpd:2.4.57
●deployment-nginx.yami
{{ include "deployment" .Values.nginx }}
※{{ include "deployment" 引数 }}で関数を呼ぶ
●●英語サイトだともっと情報がある
Helm | Built-in Objects.Filesなどのビルトインオブジェクトがあったりと、、、
GKEクラスタを作成しておく
kubectlでArgo adminとシークレット作成?
brew install argocd
Argo cd設定ファイルリポジトリのclone
argocd cluster add <context name>
argocd repo add <repo url> --ssh-private-key-path ~/.ssh/id_rsa
argocd-configuration に設定を追加
argocd-insallation に設定を追加
argo cd上からinstallationをsyncする
argocd login --grpc-web --sso dev-argocd.dev.bb.com
===
ArgoはSettingsにリポジトリ、クラスター、プロジェクト、他にUserの設定
アプリ設定でhelmのパス等を指定(Argo内部でhelm upgradeでなくkubectrl applyに変換しでやってもらえるお作法:helmコマンドのインストール不要でArgoでhelm文法が使える)
Posted by funa : 11:27 PM
| Web
| Comment (0)
| Trackback (0)